折れ線グラフ
メトリクスを可視化し、軸をカスタマイズし、プロット上で複数のラインを比較します
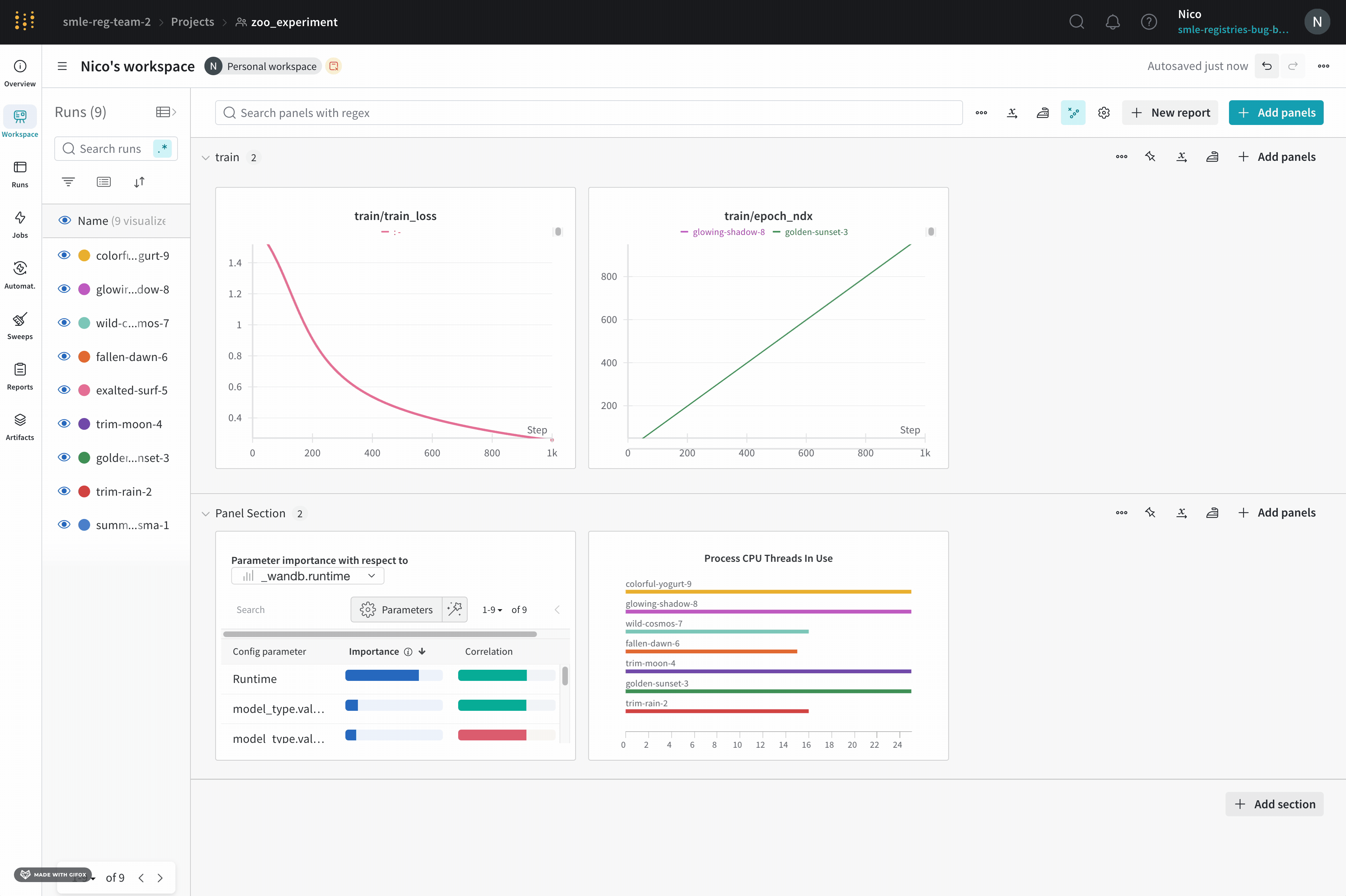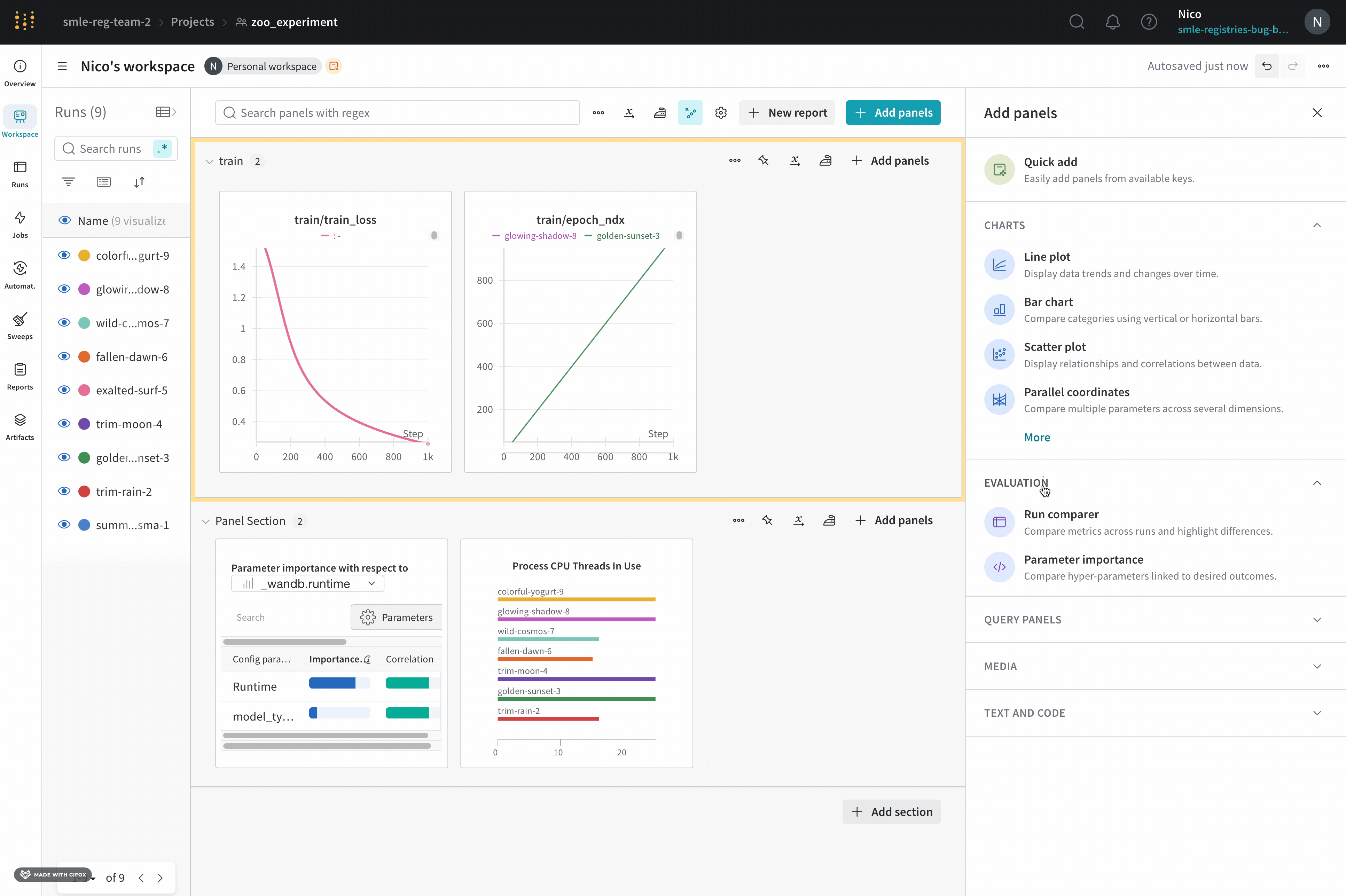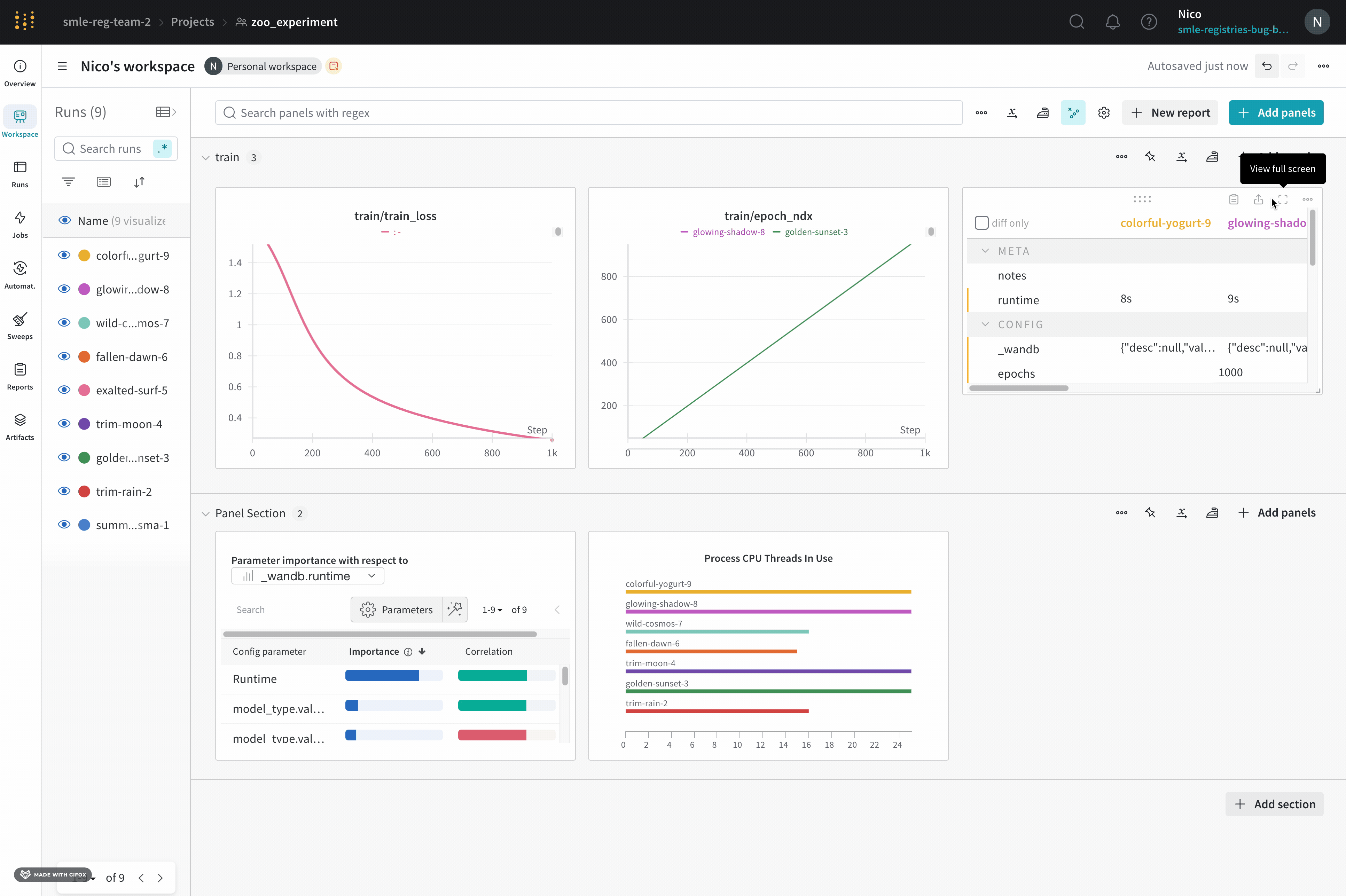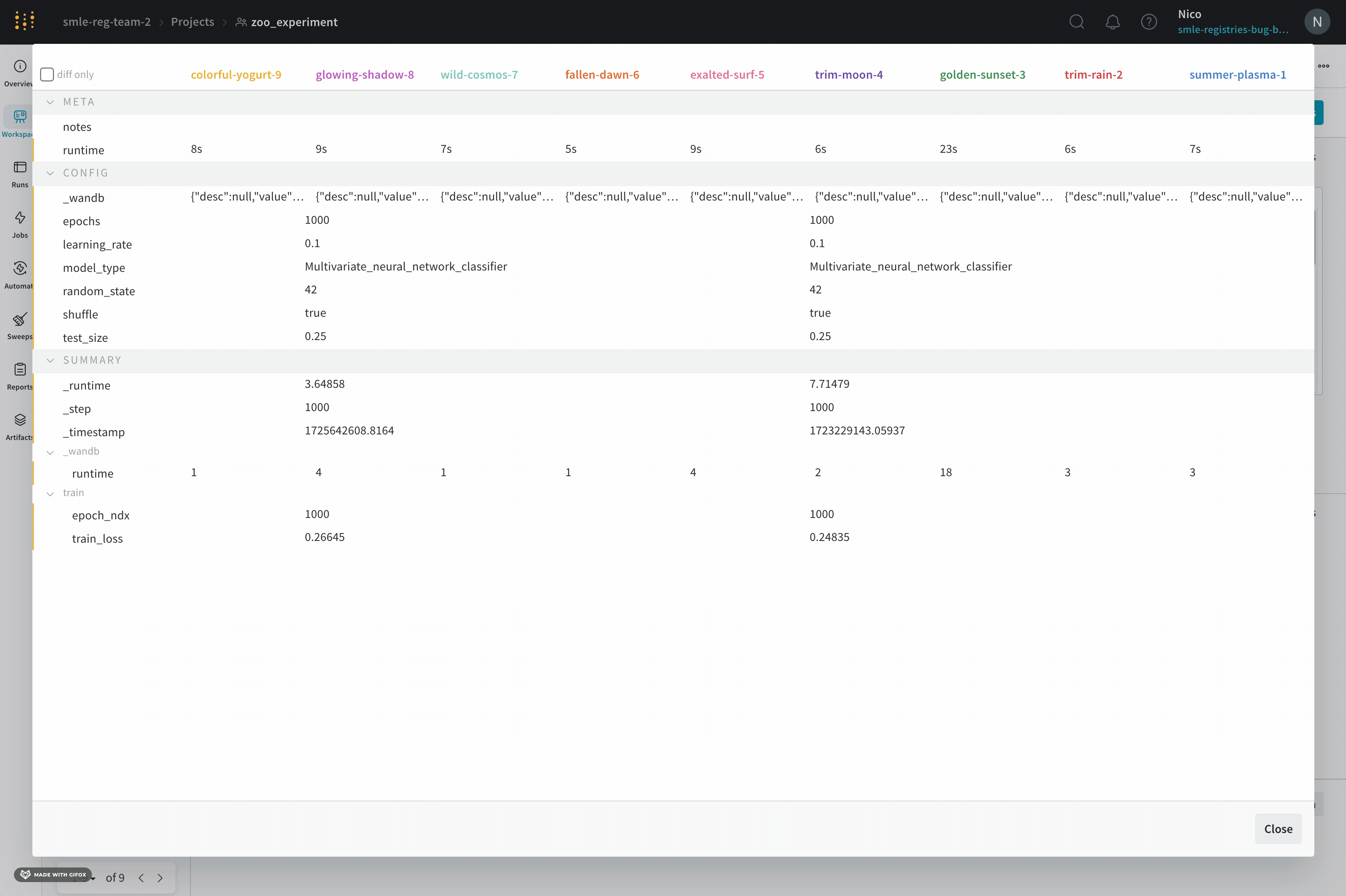
ラインプロットは、wandb.log() でメトリクスを時間経過とともにプロットするとデフォルトで表示されます。複数のラインを同じプロットで比較したり、カスタム軸を計算したり、ラベルをリネームしたりするために、チャート設定をカスタマイズできます。
ラインプロット設定を編集する
このセクションでは、個々のラインプロットパネル、セクション内のすべてのラインプロットパネル、またはワークスペース内のすべてのラインプロットパネルの設定を編集する方法を紹介します。
カスタムの x 軸を使用したい場合は、同じ wandb.log() の呼び出しで y 軸と一緒にログを取るようにしてください。
個別のラインプロット
個々のラインプロットの設定は、セクションまたはワークスペースのラインプロット設定を上書きします。ラインプロットをカスタマイズするには:
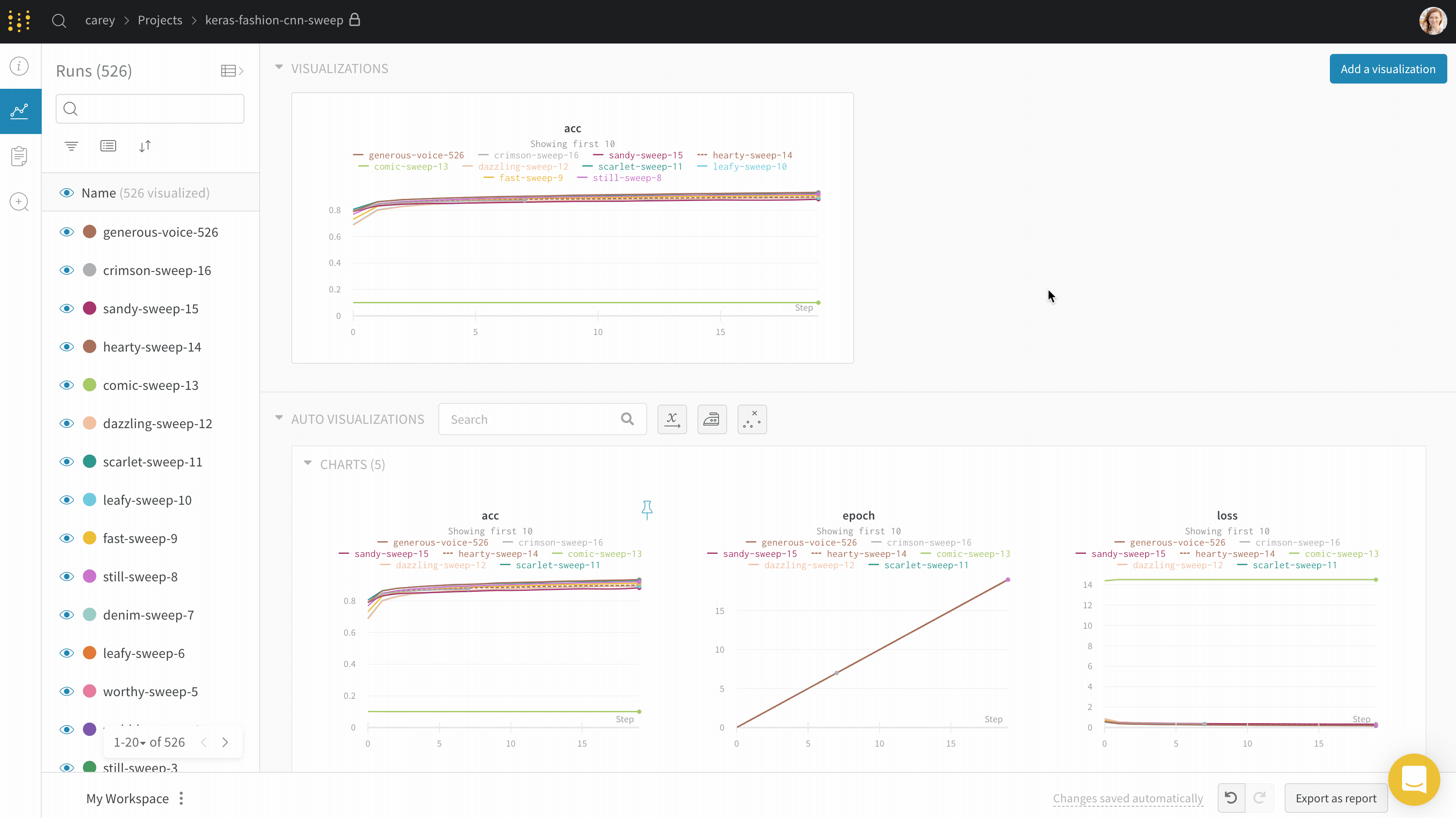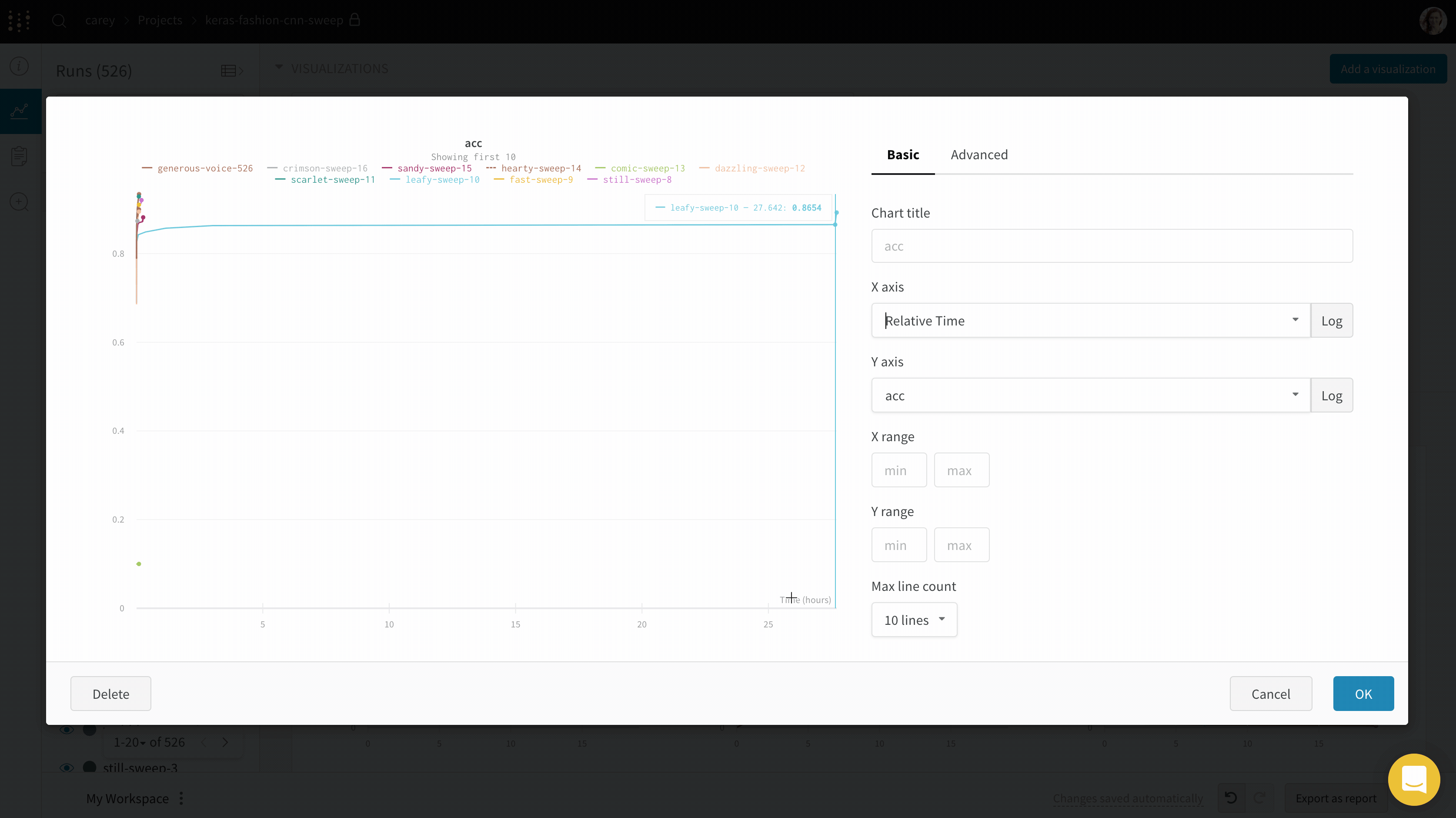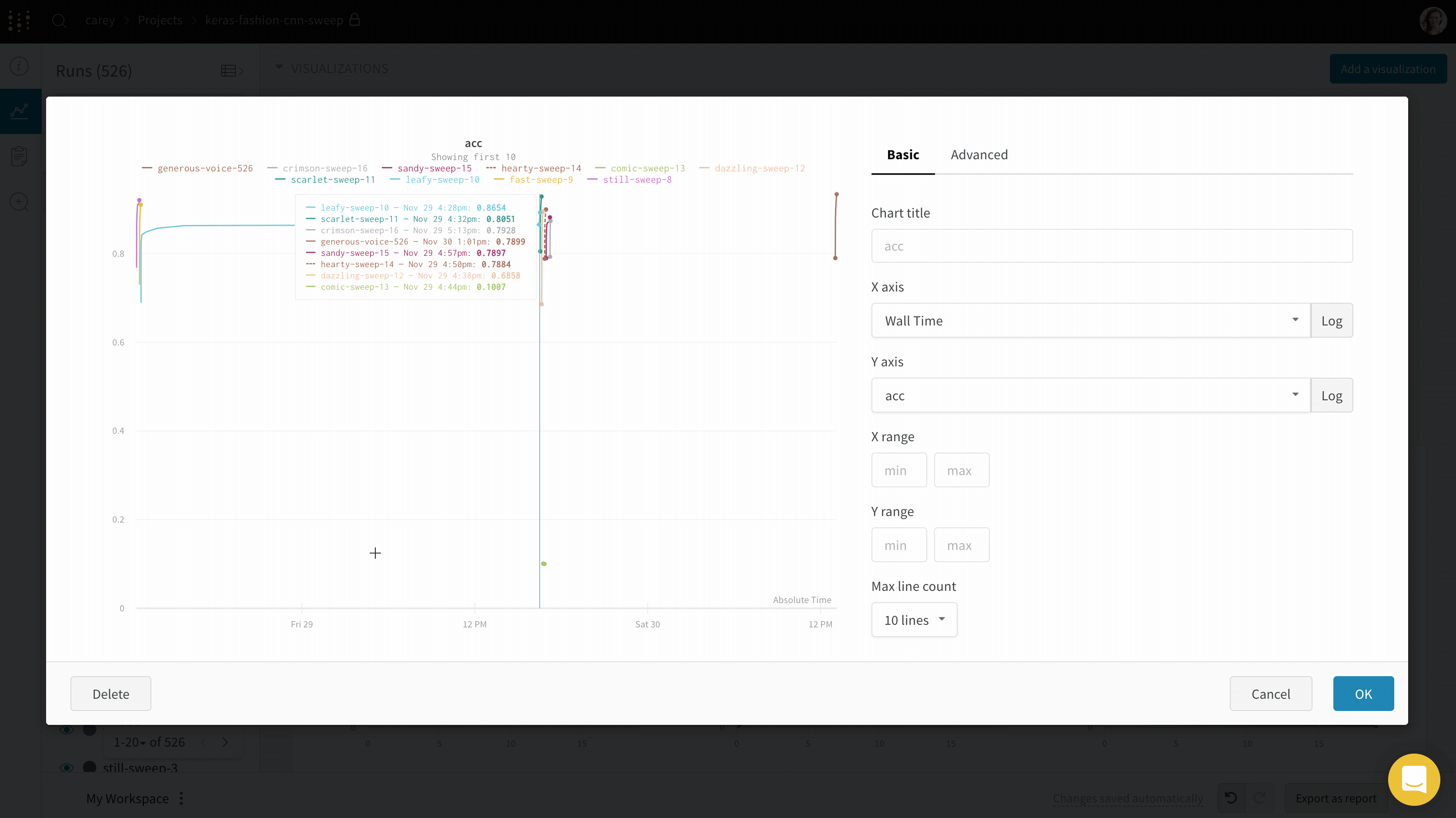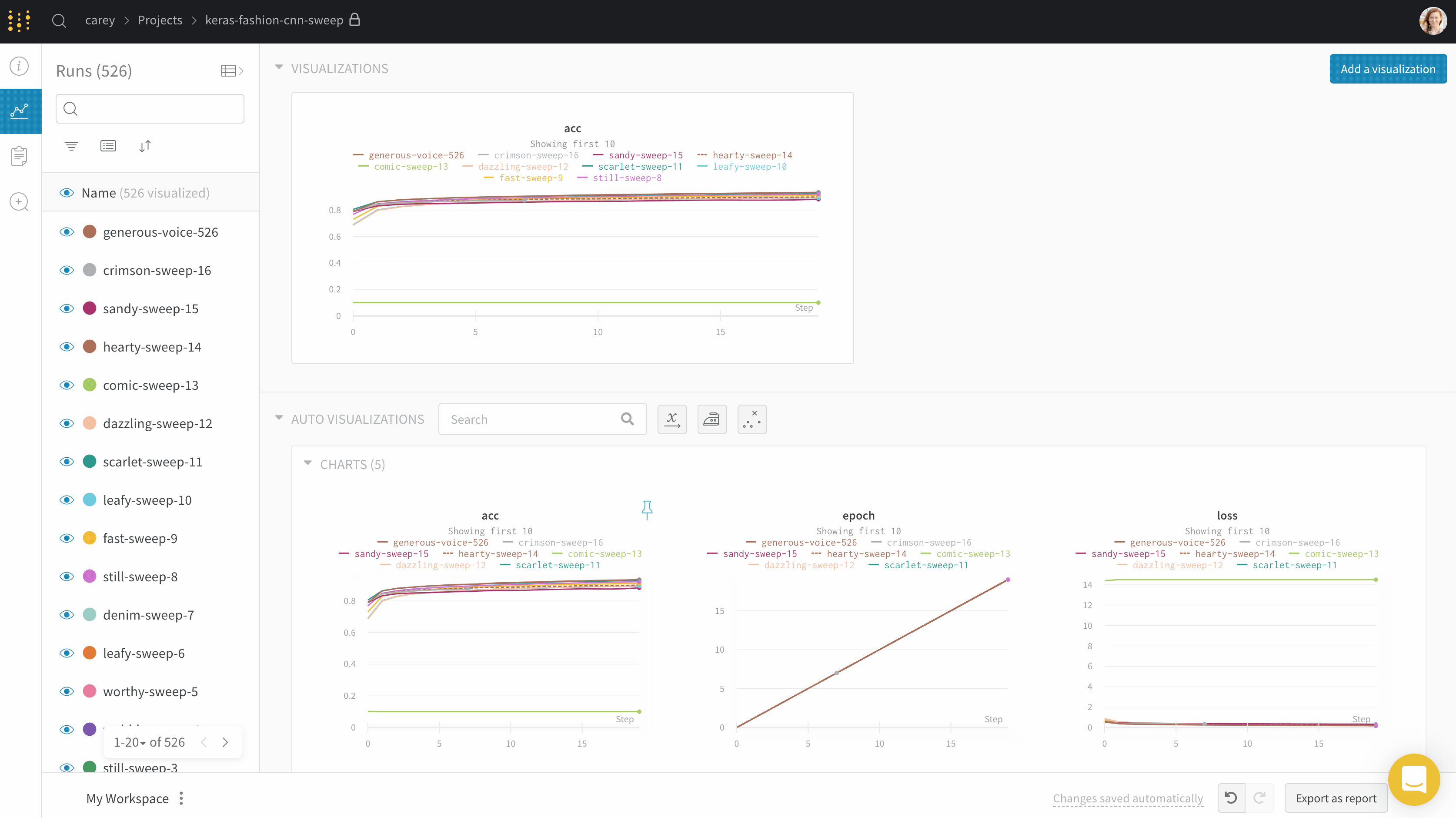
パネルの上にマウスをホバーさせ、ギアアイコンをクリックします。
表示されるモーダル内で、設定 を編集するタブを選択します。
適用 をクリックします。
ラインプロット設定
次の設定をラインプロットに設定できます:
データ : プロットのデータ表示の詳細を設定します。
X : X 軸に使用する値を選択します (デフォルトは Step です)。X 軸を 相対時間 に変更したり、W&B でログを取った値に基づいてカスタム軸を選択したりできます。
相対時間 (Wall) はプロセス開始以降の時計時間で、もし 1 日後に run を再開して何かをログした場合、それは 24 時間にプロットされます。相対時間 (プロセス) は実行中のプロセス内の時間で、もし 10 秒間 run を実行し、1 日後に再開した場合、そのポイントは 10 秒にプロットされます。ウォール時間 はグラフ上の最初の run 開始からの経過時間を示します。Step はデフォルトで wandb.log() が呼び出されるたびに増加し、モデルからログされたトレーニングステップの数を反映することになっています。
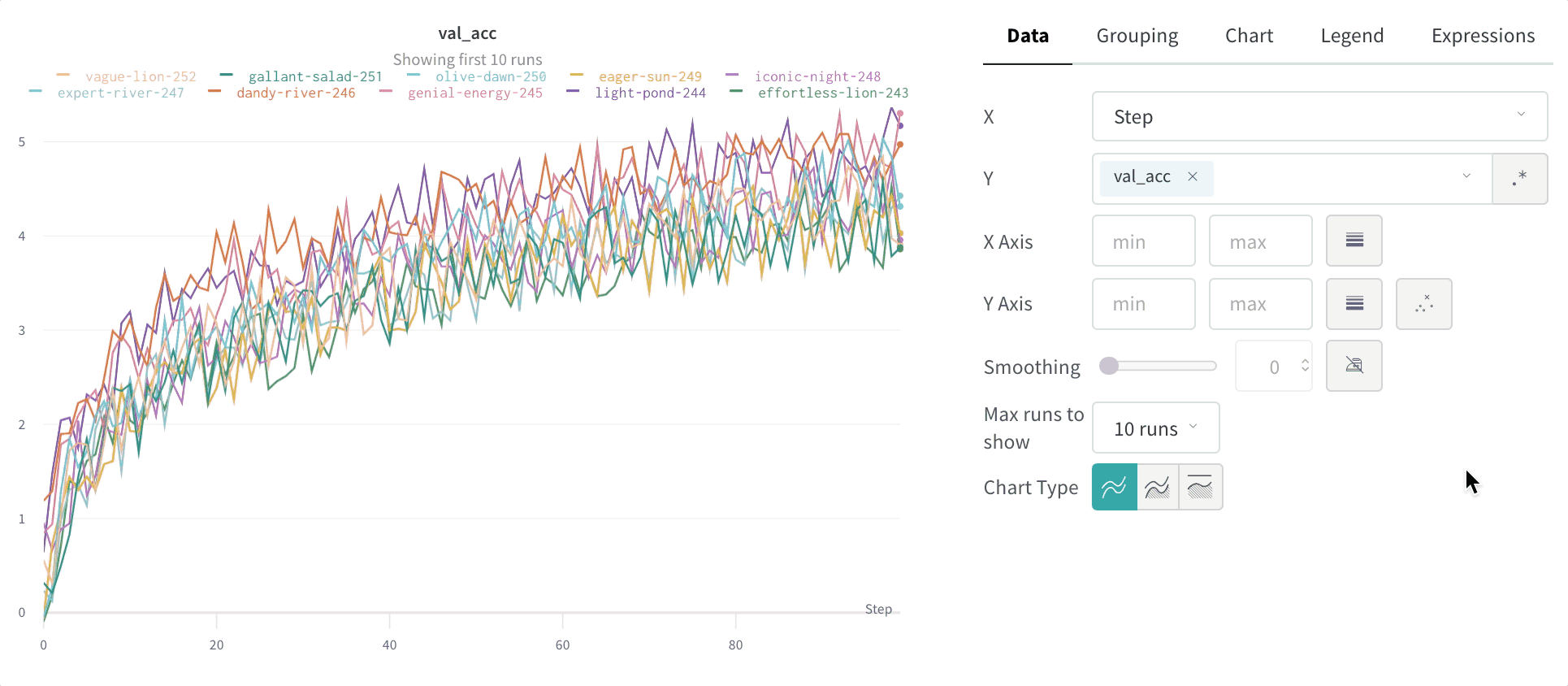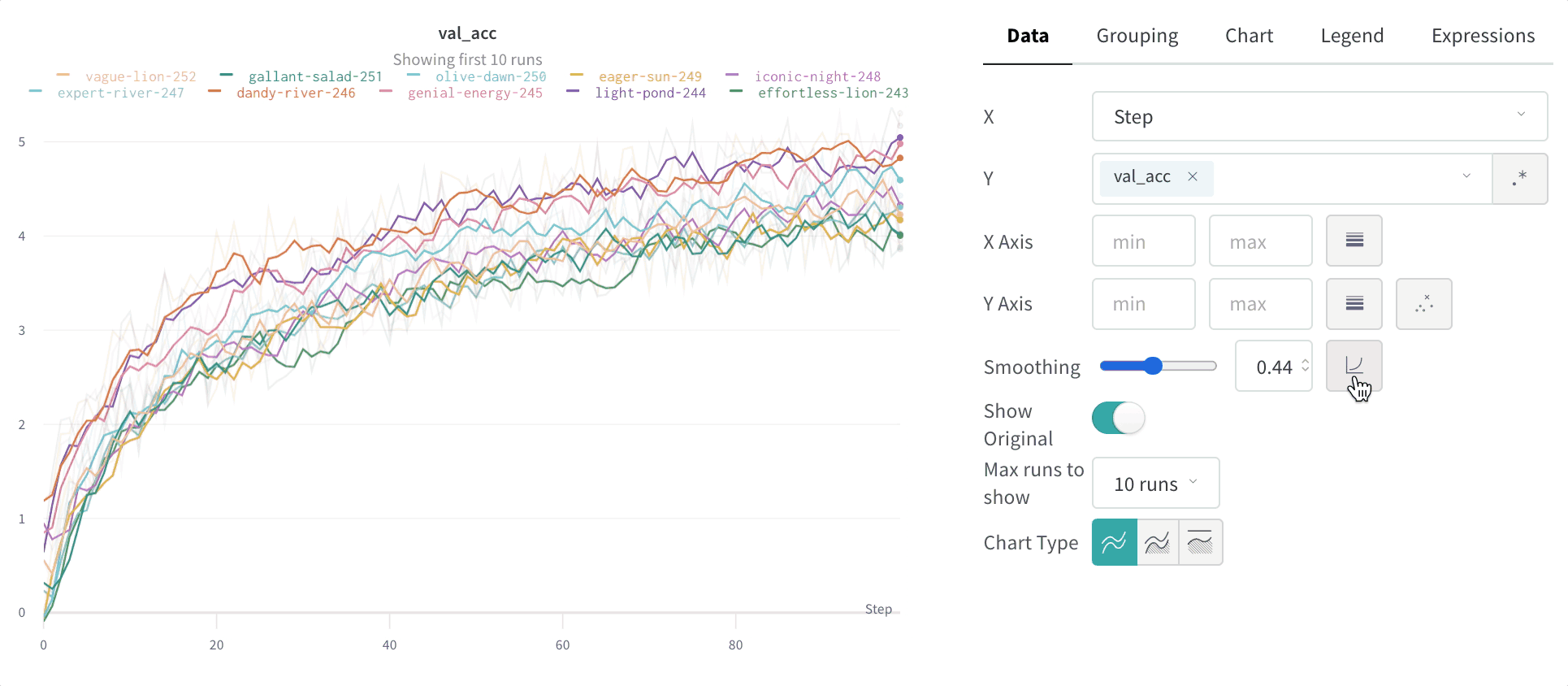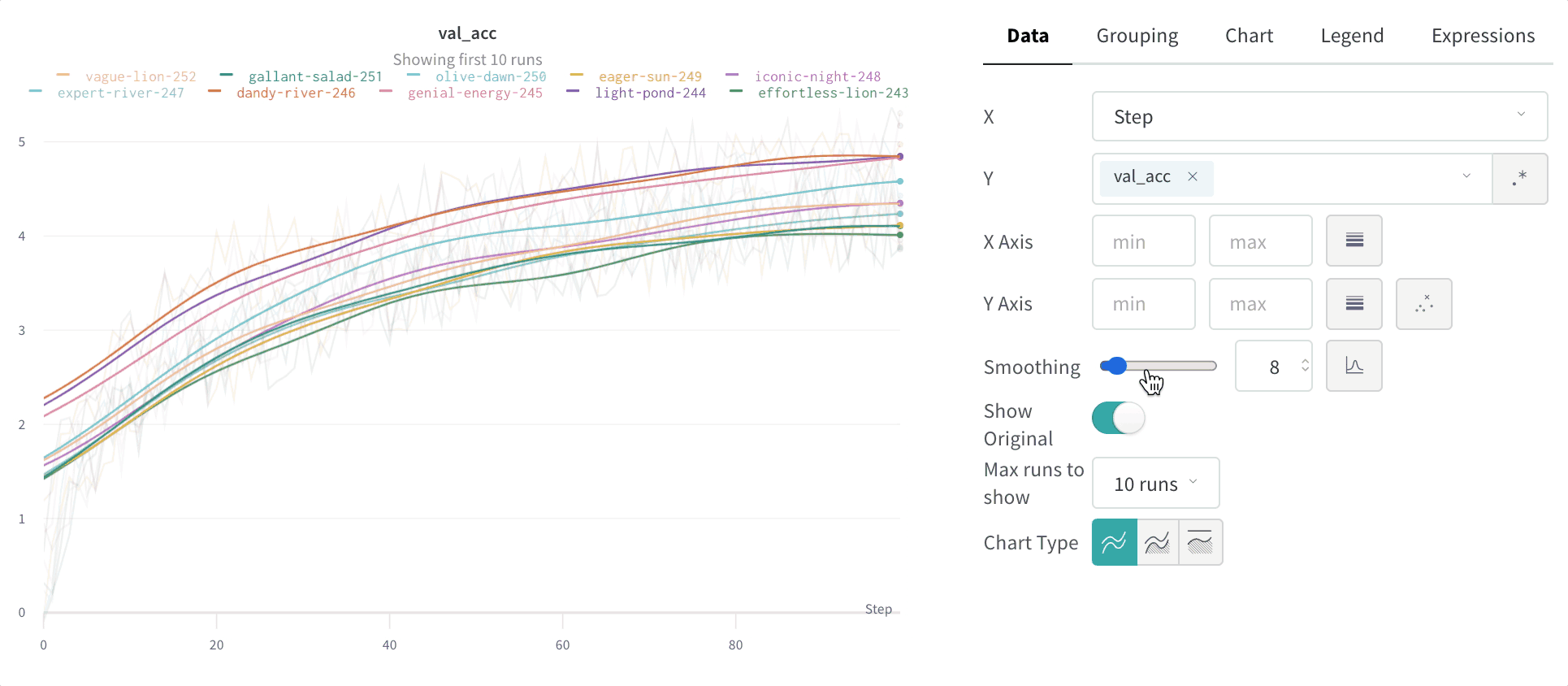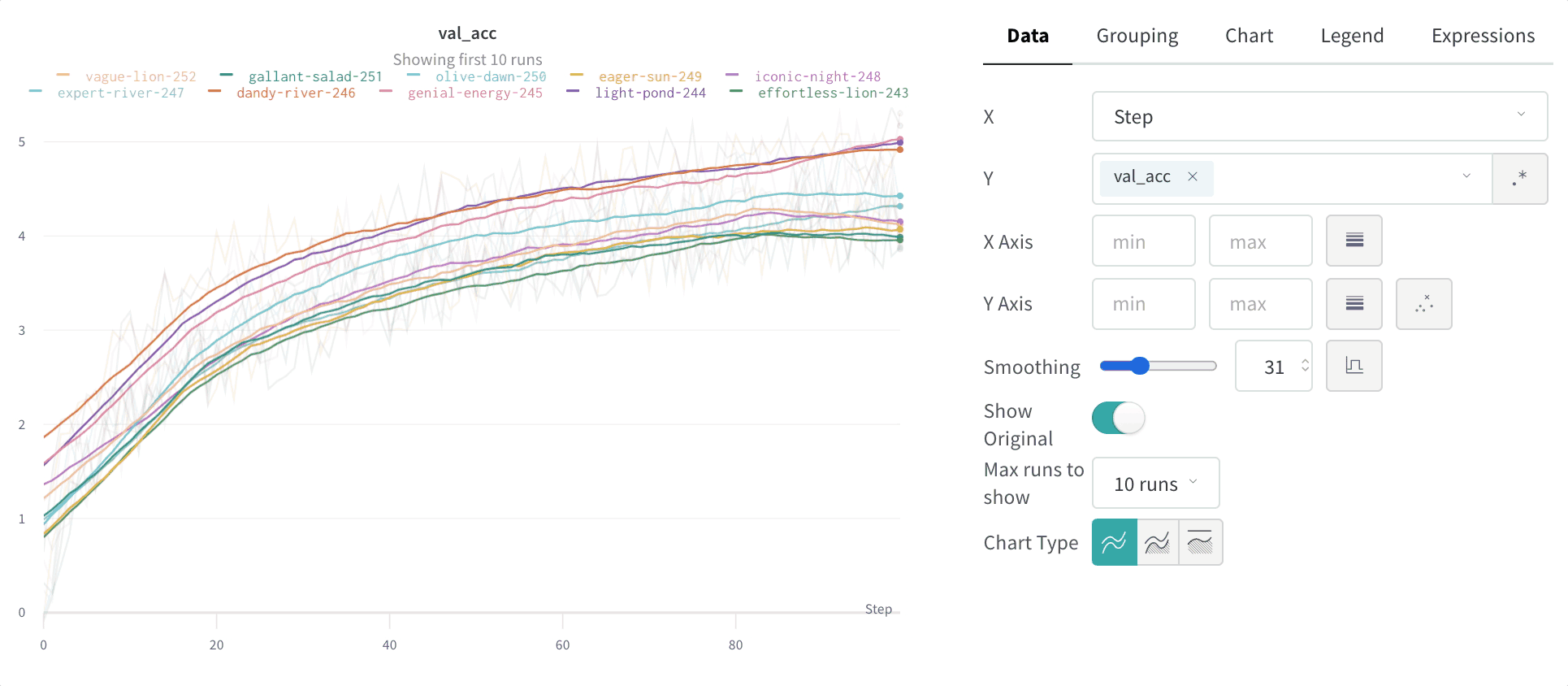
Y : メトリクスや時間経過とともに変化するハイパーパラメーターなど、ログに取られた値から1つ以上の y 軸を選択します。X軸 および Y軸 の最小値と最大値 (オプション)。ポイント集計メソッド . ランダムサンプリング (デフォルト) または フルフェデリティ 。詳細は サンプリング を参照。スムージング : ラインプロットのスムージングを変更します。デフォルトは 時間加重EMA です。その他の値には スムージングなし , ランニング平均 , および ガウシアン があります。外れ値 : 外れ値を除外して、デフォルトのプロット最小値および最大値スケールを再設定します。最大 run またはグループ数 : この数値を増やすことで、ラインプロットに一度により多くのラインを表示します。デフォルトは 10 run です。チャートの一番上に “最初の 10 run を表示中” というメッセージが表示され、利用可能な run が 10 個を超える場合、チャートが表示できる数を制約していることが分かります。チャートタイプ : ラインプロット、エリアプロット、および パーセンテージエリアプロットの中で切り替えます。
グルーピング : プロット内で run をどのようにグループ化し集計するかを設定します。
グループ化基準 : 列を選択し、その列に同じ値を持つすべての run がグループ化されます。Agg : 集計— グラフ上のラインの値です。オプションはグループの平均、中央値、最小、最大です。
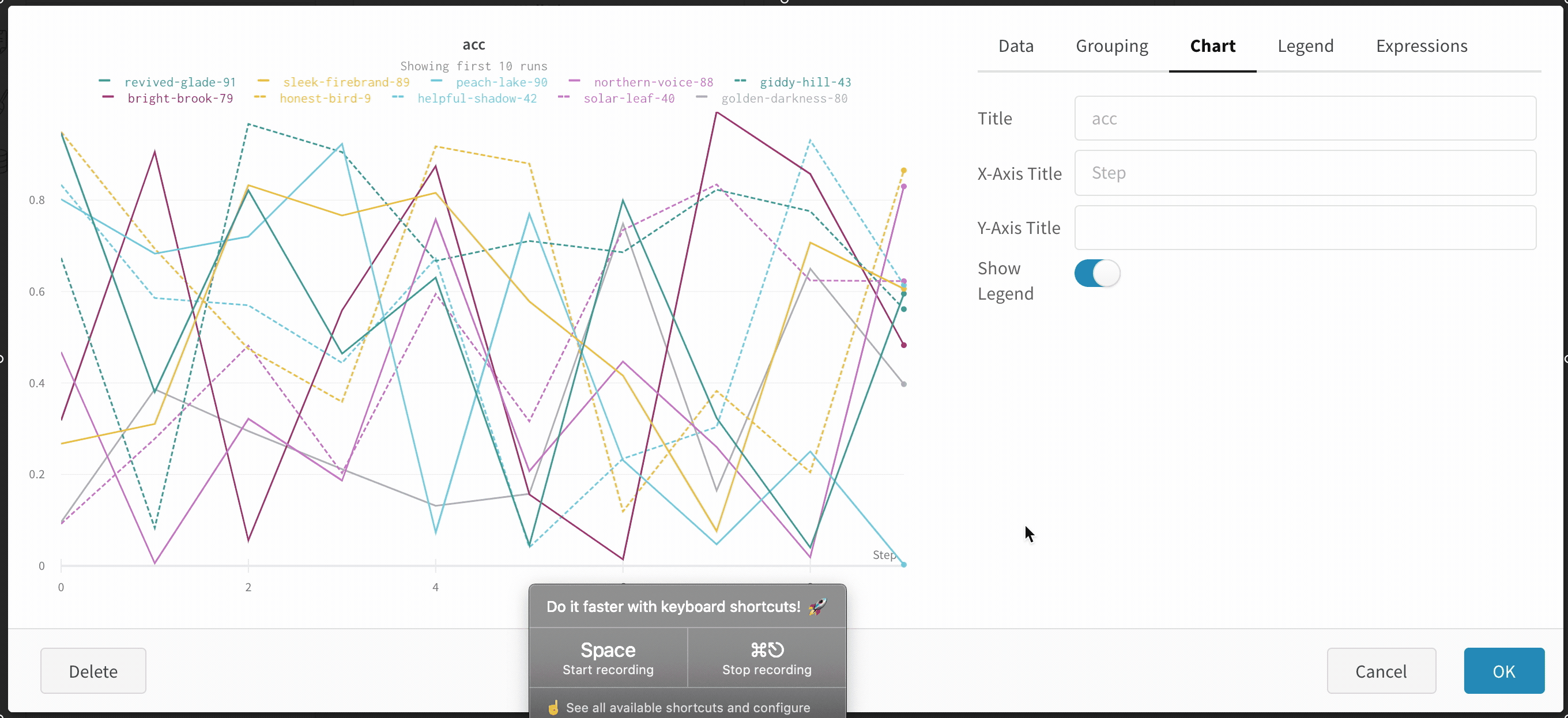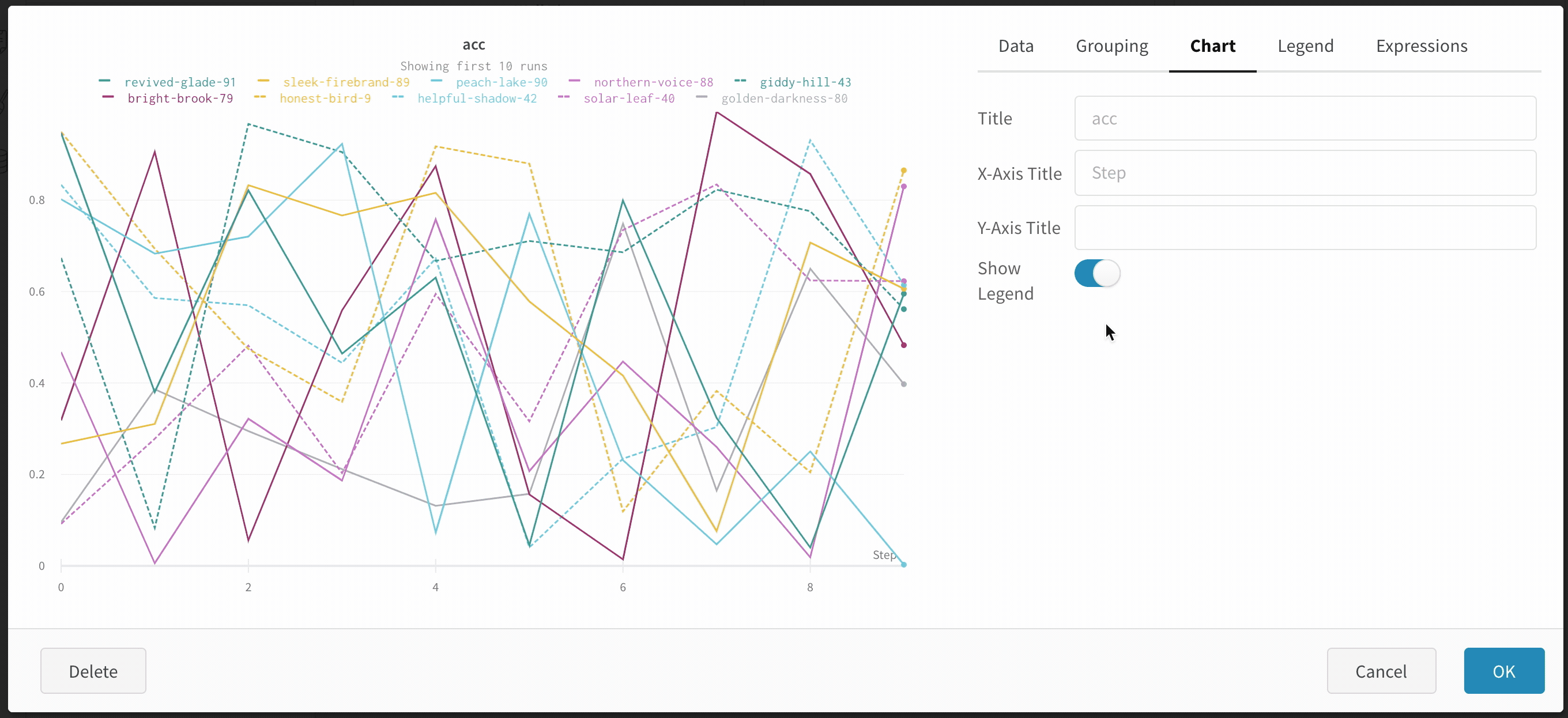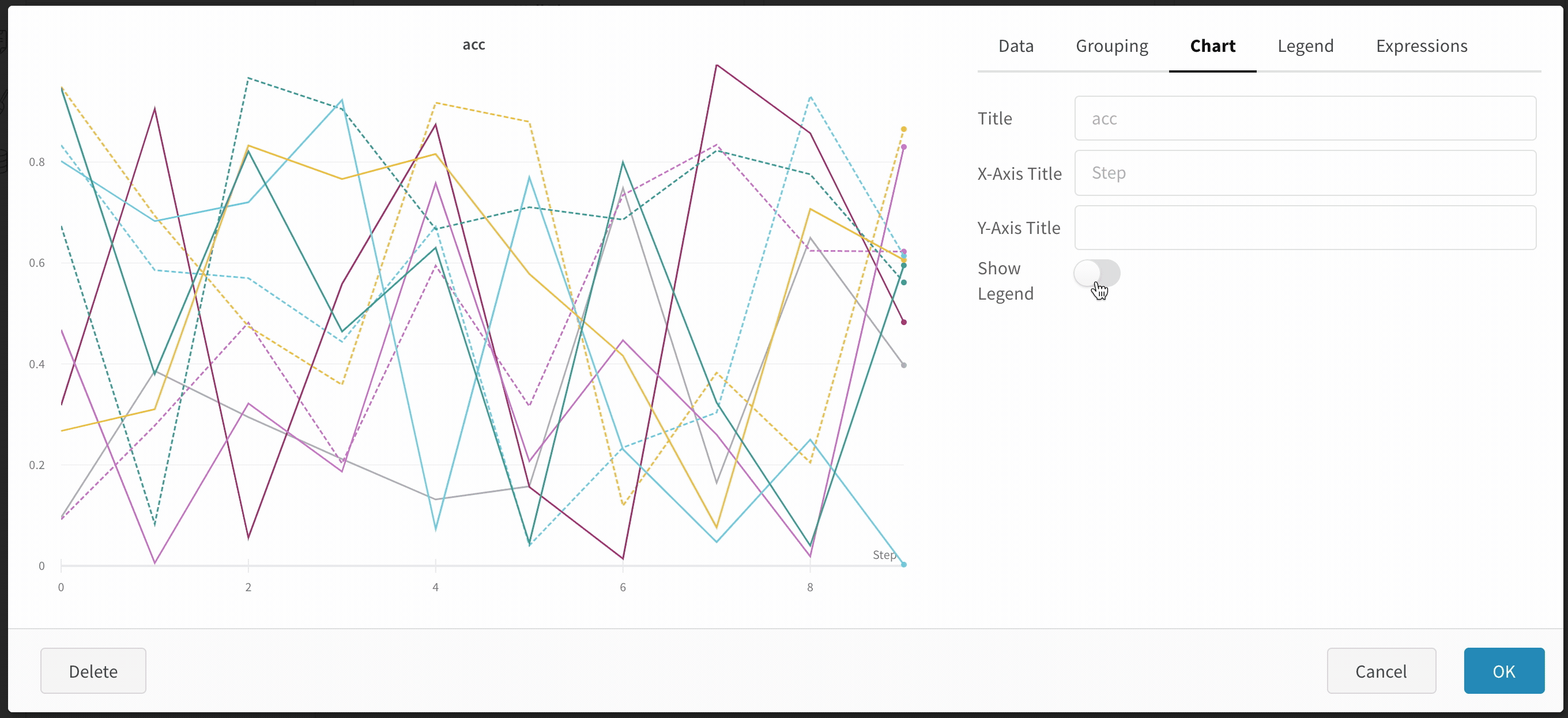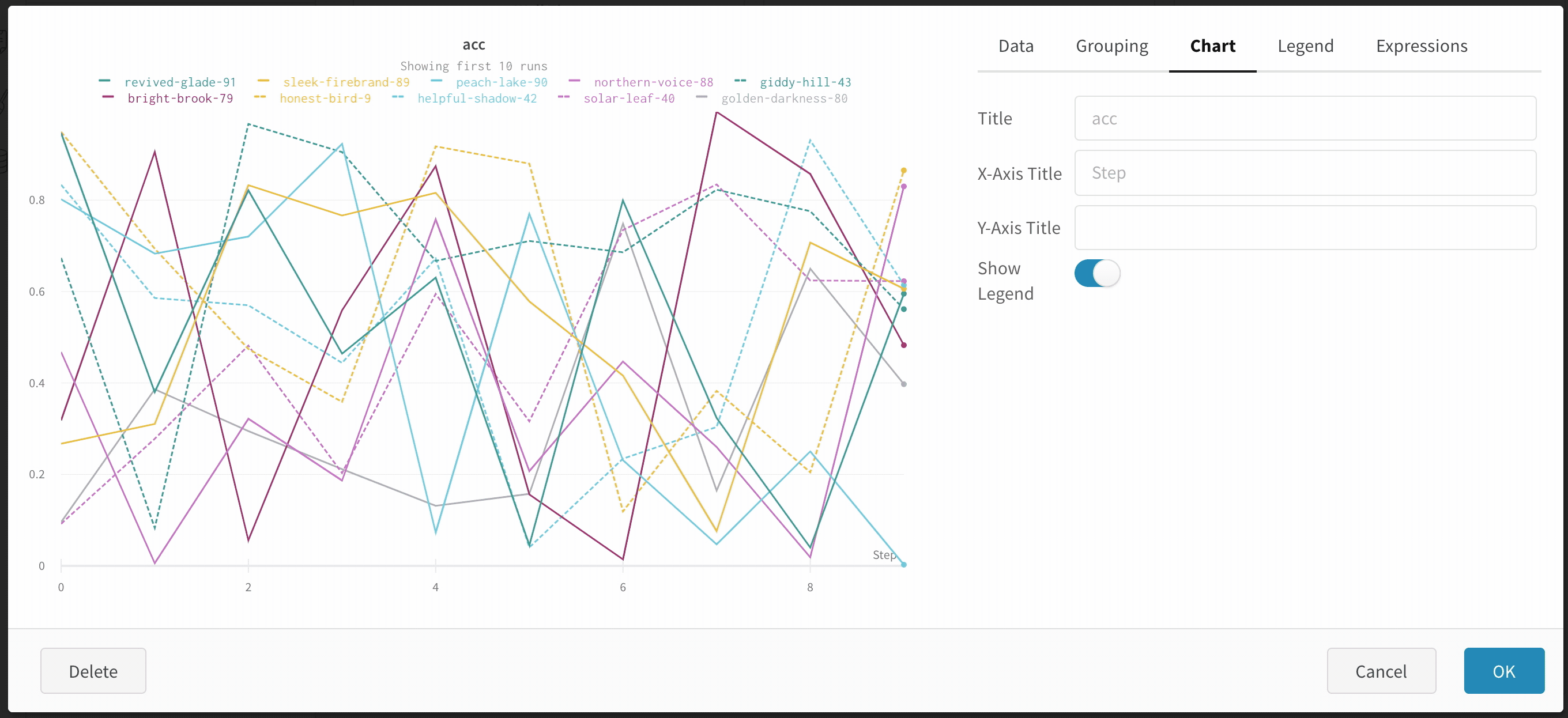
チャート : パネル、X軸、Y軸のタイトルを指定し、凡例を表示または非表示に設定し、その位置を設定します。
凡例 : パネルの凡例の外観をカスタマイズします、もし有効化されている場合。
凡例 : プロットの各ラインに対する凡例のフィールド、それぞれのラインのプロット内の凡例。凡例テンプレート : テンプレートの上部に表示される凡例およびマウスオーバー時にプロットに表示される伝説で, 表示したい具体的なテキストおよび変数を定義します。
式 : パネルにカスタム計算式を追加します。
Y軸式 : グラフに計算されたメトリクスを追加。ログされたメトリクスやハイパーパラメーターのような設定値を使用してカスタムラインを計算することができます。X軸式 : 計算された値を使用して x 軸を再スケーリングします。有用な変数には、デフォルトの x 軸の step ${summary:value} です。
セクション内のすべてのラインプロット
ワークスペースの設定を上書きして、セクション内のすべてのラインプロットのデフォルトの設定をカスタマイズするには:
セクションのギアアイコンをクリックして設定を開きます。
表示されるモーダル内で、データ または 表示設定 タブを選択して、セクションのデフォルトの設定を構成します。各 データ 設定の詳細については、前述のセクション 個別のラインプロット を参照してください。各表示設定の詳細については、セクションレイアウトの構成 を参照してください。
ワークスペース内のすべてのラインプロット
ワークスペース内のすべてのラインプロットのデフォルト設定をカスタマイズするには:
設定 というラベルの付いたギアがあるワークスペースの設定をクリックします。ラインプロット をクリックします。表示されるモーダル内で、データ または 表示設定 タブを選択して、ワークスペースのデフォルト設定を構成します。
プロット上で平均値を可視化する
複数の異なる実験があり、その値の平均をプロットで見たい場合は、テーブルのグルーピング機能を使用できます。runテーブルの上部で “グループ化” をクリックし、“すべて” を選択してグラフに平均値を表示します。
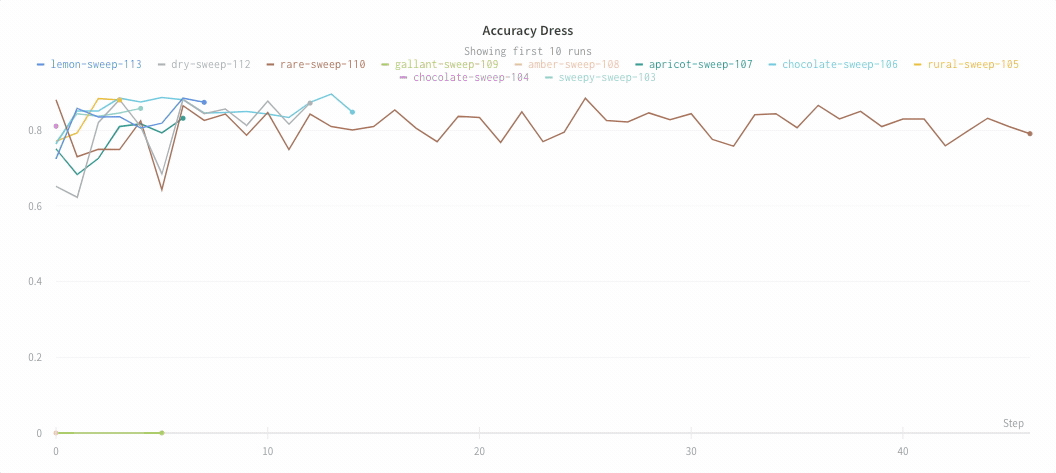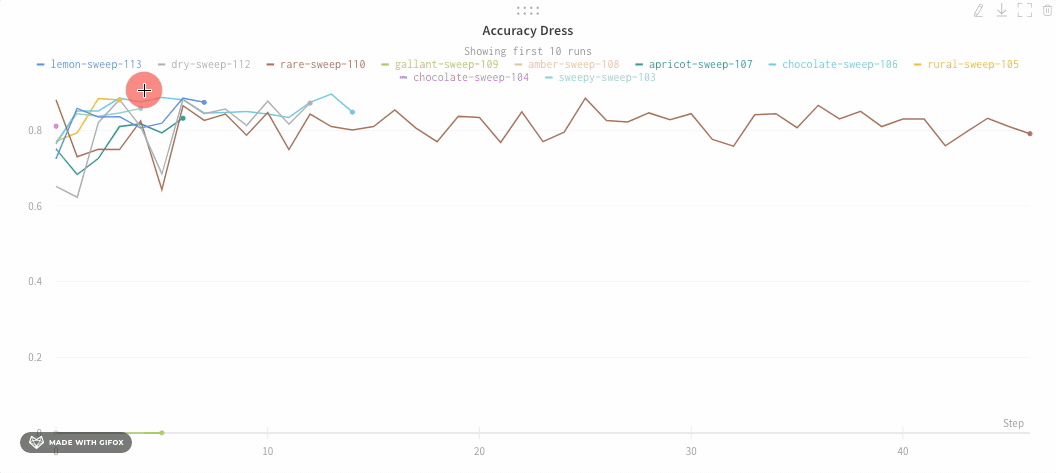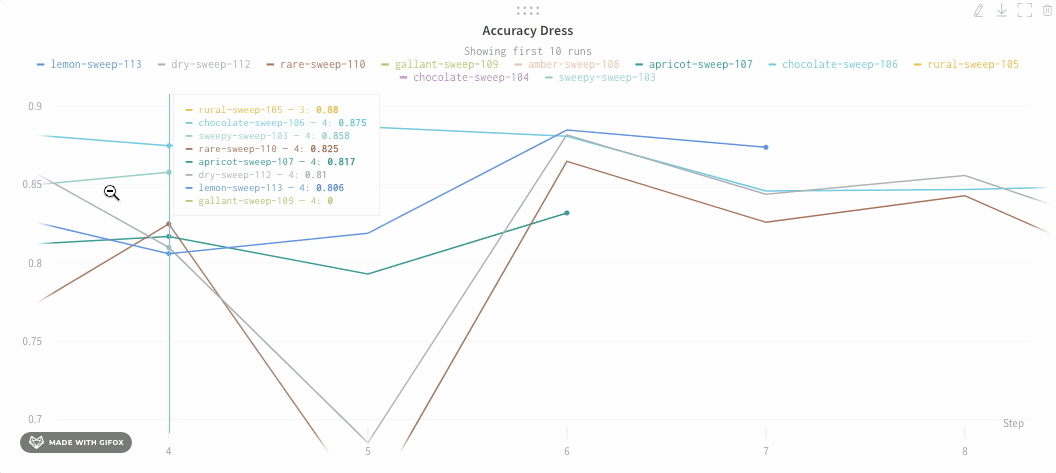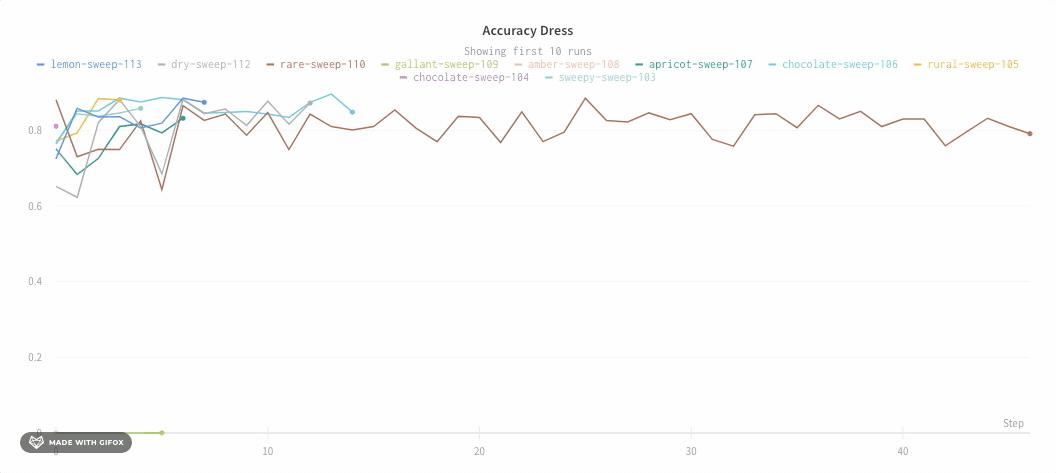
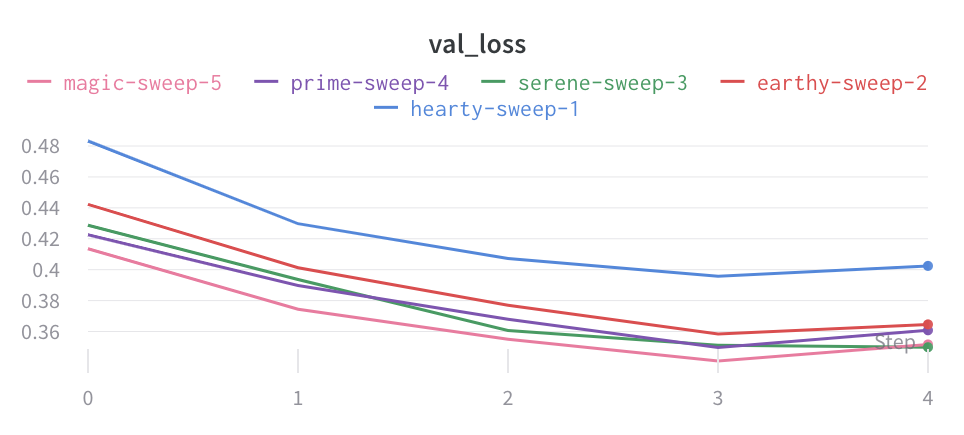
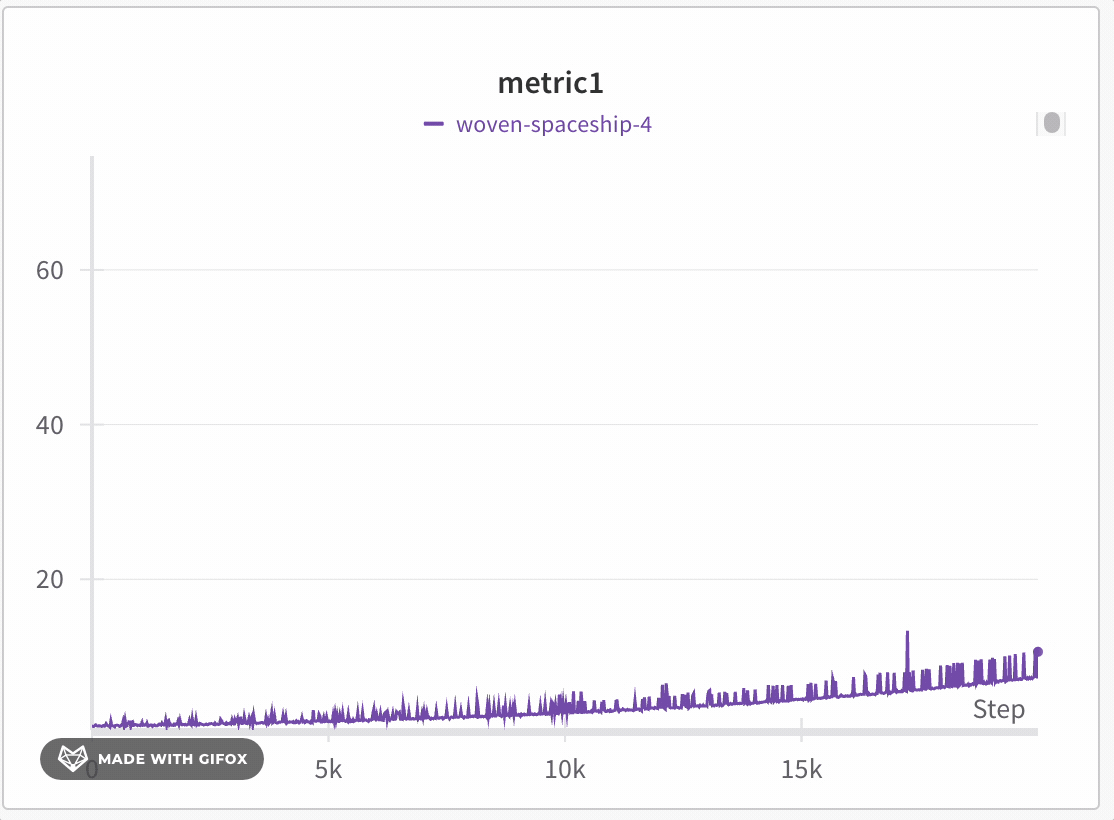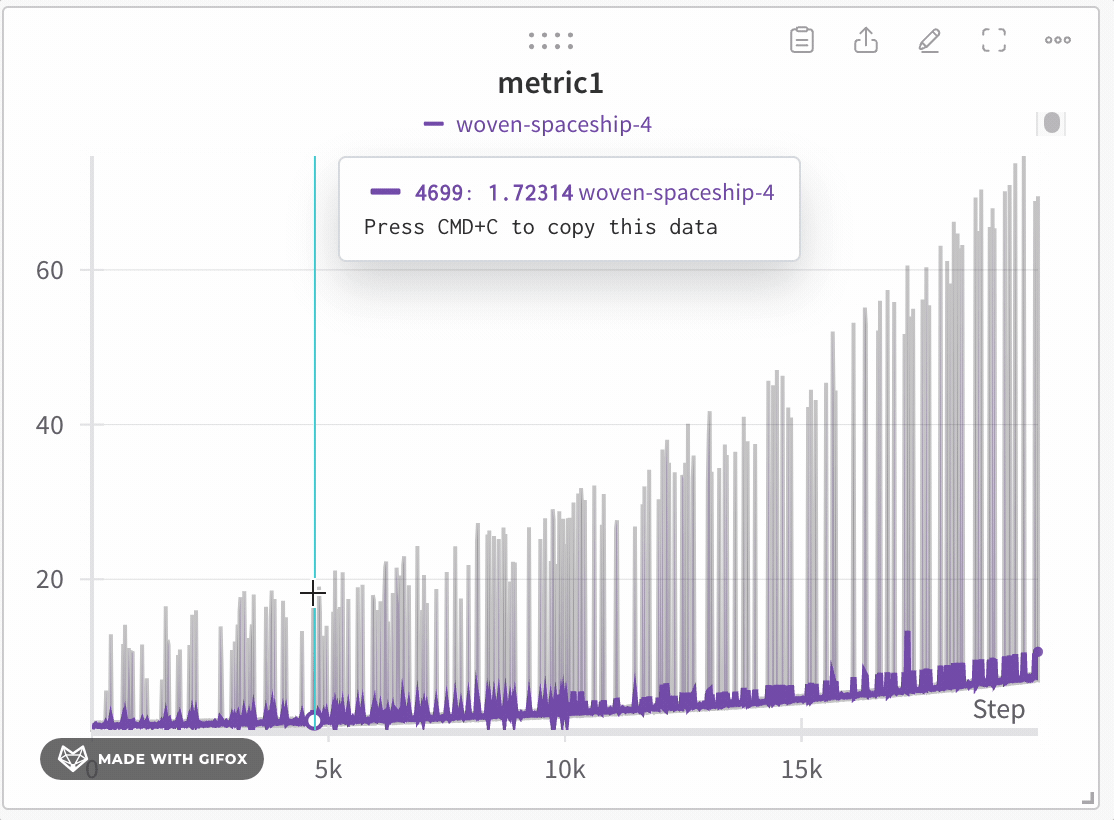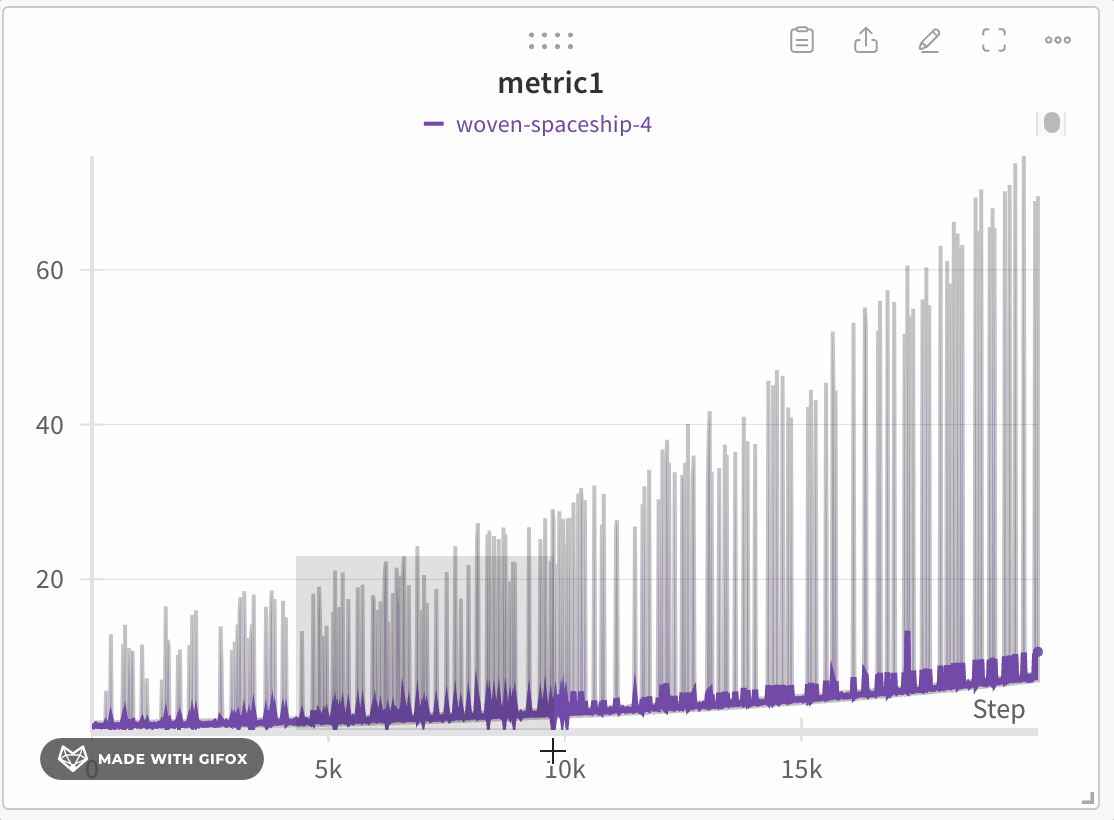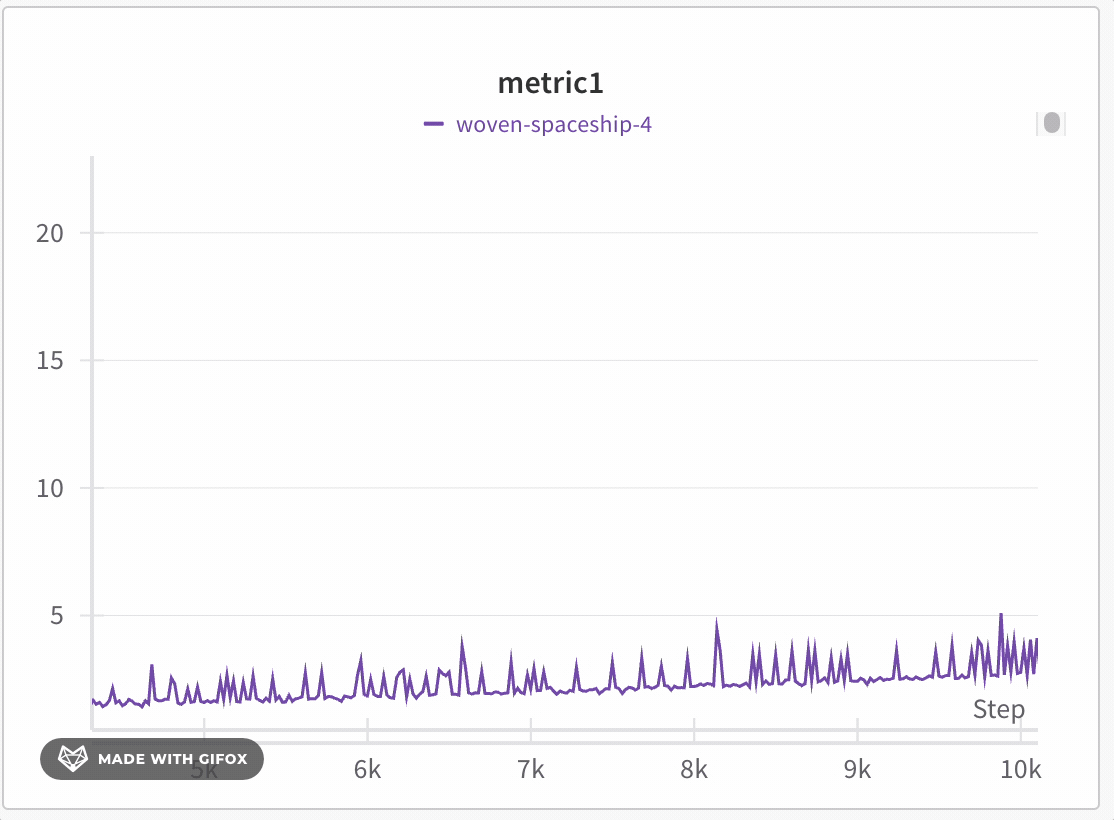
以下は平均化する前のグラフの例です:
次の画像は、グループ化されたラインを使用して run における平均値を示すグラフです。
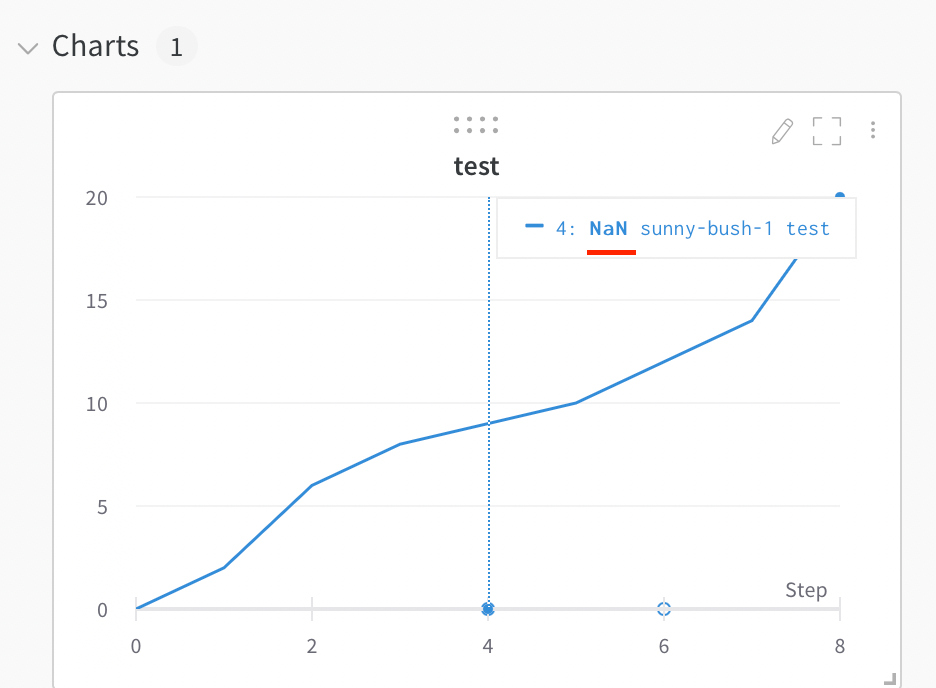
プロット上で NaN 値を可視化する
wandb.log を使用して、PyTorch テンソルを含む NaN 値をラインプロットでプロットすることもできます。例えば:
wandb. log({"test" : [... , float("nan" ), ... ]})
2 つのメトリクスを 1 つのチャートで比較する
ページの右上隅にある パネルを追加 ボタンを選択します。
表示される左側のパネルで評価のドロップダウンを展開します。
Run comparer を選択します。
ラインプロットの色を変更する
時々、run のデフォルトの色が比較には適していないことがあります。この問題を解決するために、wandb は手動で色を変更できる2つの方法を提供しています。
各 run は初期化時にデフォルトでランダムな色が割り当てられます。
どの色をクリックすると、手動で選択できるカラーパレットが表示されます。
設定を編集したいパネルにマウスをホバーさせます。
表示される鉛筆アイコンを選択します。
凡例 タブを選択します。
異なる x 軸で可視化する
実験がかかった絶対時間を見たい場合や、実験が実行された日を見たい場合は、x 軸を切り替えることができます。ここでは、ステップから相対時間、そして壁時間に切り替える例を示します。
エリアプロット
詳細設定タブでさまざまなプロットスタイルをクリックすると、エリアプロットまたはパーセンテージエリアプロットを取得できます。
ズーム
直線をクリックしてドラッグすると垂直および水平方向に同時にズームします。これにより、x軸とy軸のズームが変更されます。
チャートの凡例の非表示
この簡単なトグルでラインプロットの凡例をオフにできます:
1 - 折れ線グラフのリファレンス
X軸
折れ線グラフのX軸を、W&B.logで記録した任意の値に設定できます。ただし、それが常に数値として記録されている必要があります。
Y軸の変数
Y軸の変数は、wandb.logで記録した任意の値に設定できます。ただし、数値、数値の配列、または数値のヒストグラムを記録している必要があります。変数に対して1500点以上を記録した場合、W&Bは1500点にサンプリングします。
Y軸のラインの色は、runsテーブルでrunの色を変更することで変更できます。
X範囲とY範囲
プロットのXとYの最大値と最小値を変更できます。
X範囲のデフォルトは、X軸の最小値から最大値までです。
Y範囲のデフォルトは、メトリクスの最小値と0からメトリクスの最大値までです。
最大run/グループ数
デフォルトでは、10 runまたはrunのグループのみがプロットされます。runは、runsテーブルまたはrunセットの上位から取得されるため、runsテーブルやrunセットを並べ替えると、表示されるrunを変更できます。
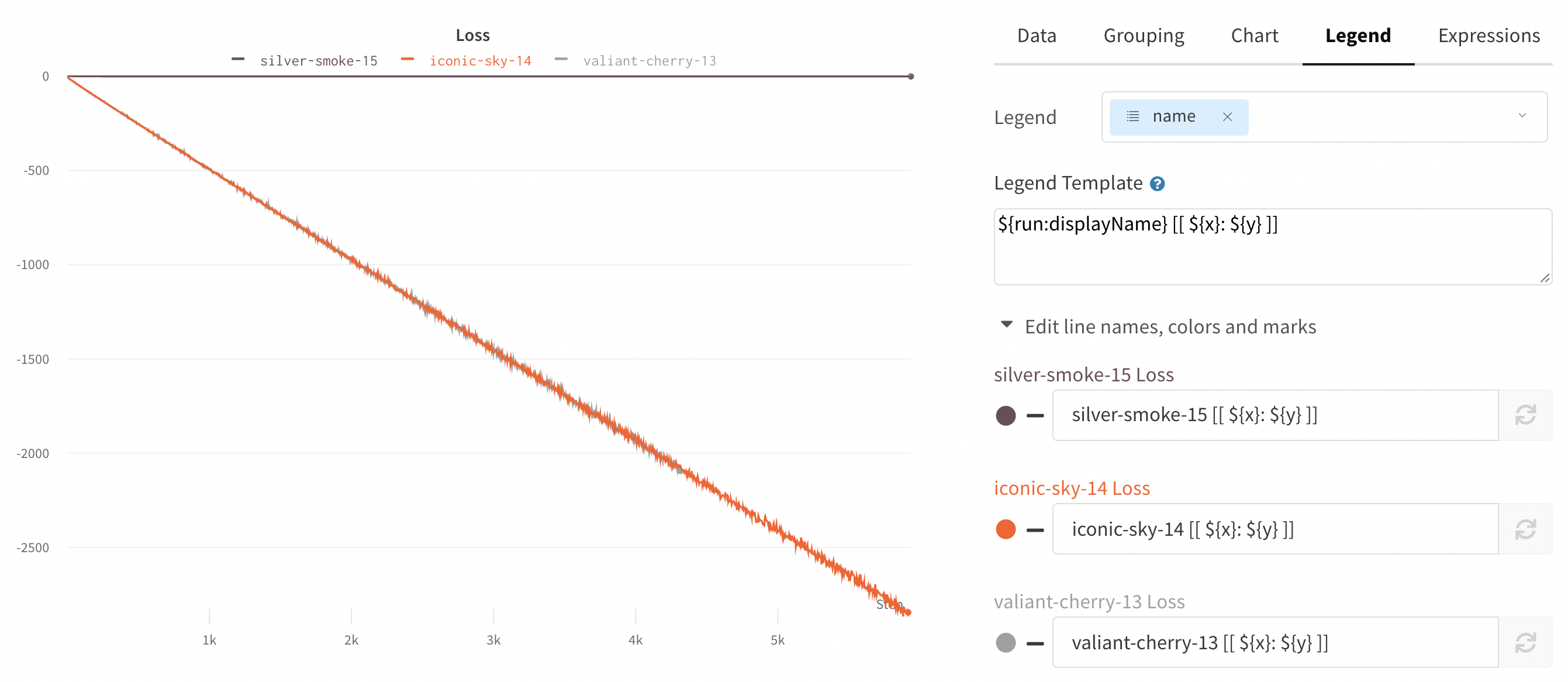
凡例
チャートの凡例を制御して、任意のrunに対して記録した任意のconfig値やrunのメタデータ、例えば作成日時やrunを作成したユーザーを表示できます。
例:
${run:displayName} - ${config:dropout} は、各runの凡例名を royal-sweep - 0.5 のようにします。ここで royal-sweep はrun名で、0.5 は dropout という名前のconfigパラメータです。
グラフにカーソルを合わせたときにクロスヘアで特定の点の値を表示するために、[[ ]] 内に値を設定できます。例えば \[\[ $x: $y ($original) ]] は “2: 3 (2.9)” のように表示されます。
[[ ]] 内でサポートされる値は以下の通りです:
値
意味
${x}X値
${y}Y値(平滑化調整を含む)
${original}平滑化調整を含まないY値
${mean}グループ化されたrunの平均
${stddev}グループ化されたrunの標準偏差
${min}グループ化されたrunの最小値
${max}グループ化されたrunの最大値
${percent}全体のパーセント(積み上げ面チャート用)
グループ化
全てのrunをグループ化するか、個々の変数でグループをすることができます。また、テーブル内部でグループ化することによってグループを有効にすると、そのグループは自動的にグラフに反映されます。
スムージング
スムージング係数を0から1の間で設定できます。0はスムージングなし、1は最大スムージングを意味します。詳細はスムージング係数の設定について を参照してください。
外れ値を無視
デフォルトのプロットの最小値と最大値のスケールから外れ値を除外するようにプロットをリスケールします。この設定がプロットに与える影響は、プロットのサンプリングモードに依存します。
ランダムサンプリングモード を使用するプロットでは、外れ値を無視 を有効にすると、5%から95%の点のみが表示されます。外れ値が表示される場合、それらは他の点と異なるフォーマットでは表示されません。完全な忠実度モード を使用するプロットでは、全ての点が常に表示され、各バケットの最後の値まで凝縮されます。外れ値を無視 が有効になっている場合、各バケットの最小値と最大値の境界がシェーディングされます。それ以外の場合は、領域はシェーディングされません。
式の表現
式の表現を使用して、1-accuracyのようにメトリクスから派生した値をプロットできます。現在、単一のメトリクスをプロットしている場合にのみ機能します。+、-、*、/、%といった簡単な算術式、および**を使用してべき乗を行うことができます。
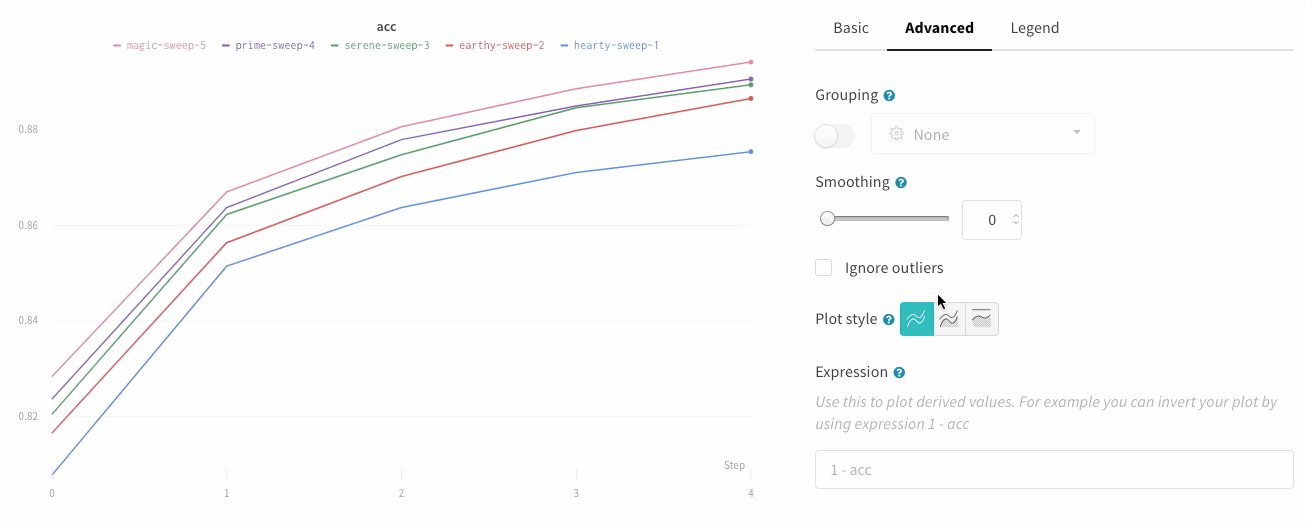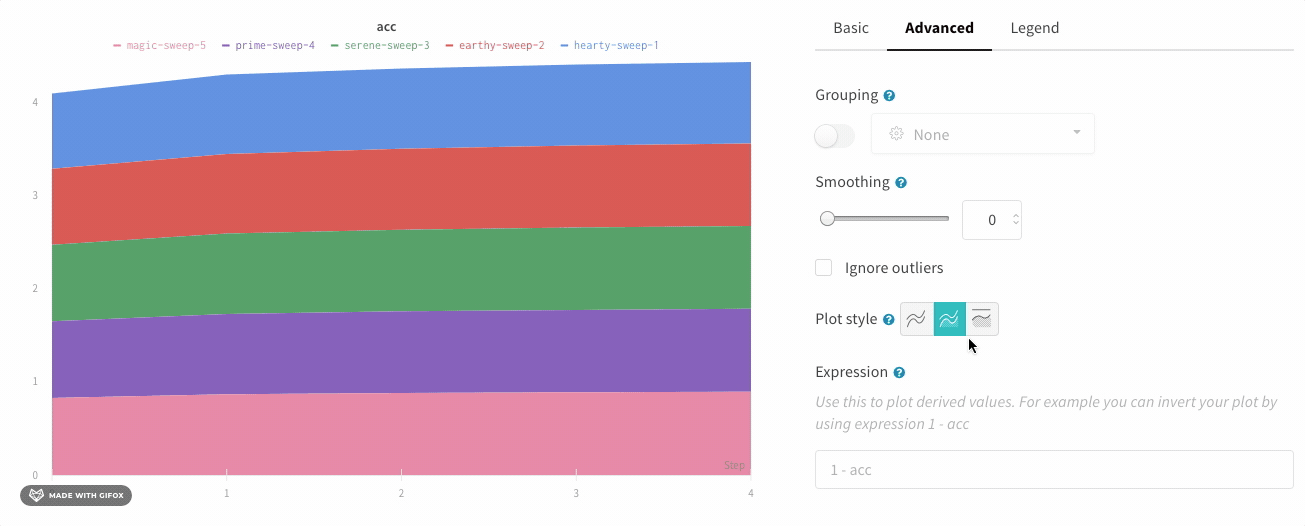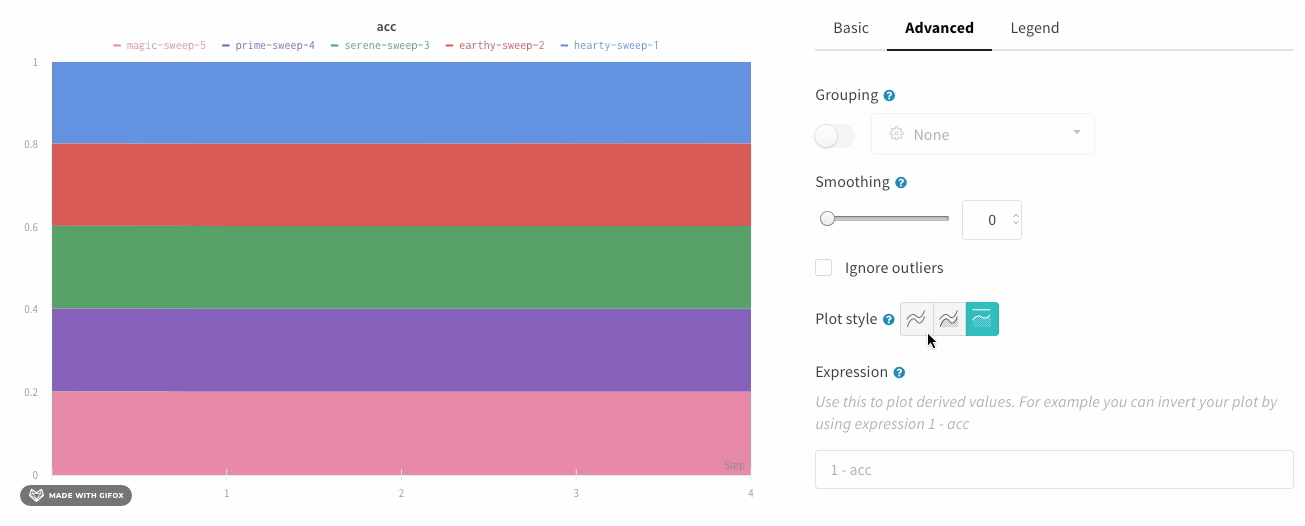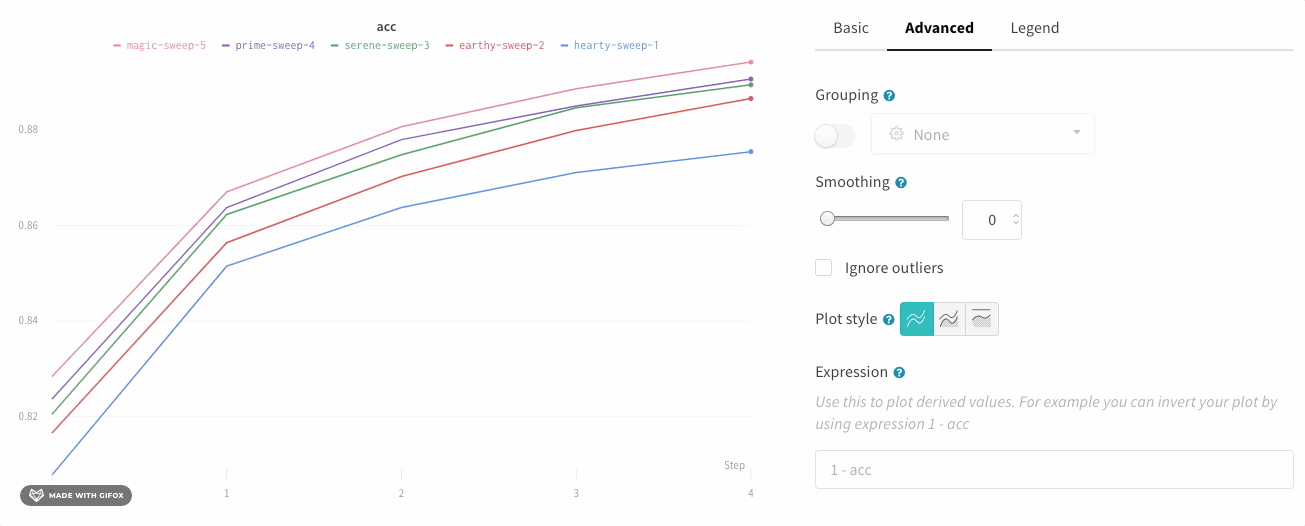
プロットスタイル
折れ線グラフのスタイルを選択します。
折れ線プロット:
面プロット:
パーセンテージエリアプロット:
2 - ポイント集約
Use point aggregation methods within your line plots for improved data visualization accuracy and performance. There are two types of point aggregation modes: full fidelity and random sampling . W&B uses full fidelity mode by default.
Full fidelity
Full fidelity modeを使用すると、W&Bはデータポイントの数に基づいてx軸を動的なバケットに分割します。そして、それぞれのバケット内の最小、最大、平均値を計算し、線プロットのポイント集約をレンダリングします。
フルフィデリティモードを使用する際のポイント集約の3つの主な利点は次のとおりです:
極値とスパイクを保持する: データ内の極値とスパイクを保持します。
最小値と最大値のレンダリングを設定する: W&Bアプリを使用して、極値(最小/最大)を影付きエリアとして表示するかどうかをインタラクティブに決定できます。
データの忠実度を失わずにデータを探索する: W&Bは特定のデータポイントにズームインするとx軸のバケットサイズを再計算します。これにより、正確さを失うことなくデータを探索できることを保証します。キャッシュを使用して以前に計算された集計を保存することで、ロード時間を短縮するのに役立ちます。これは、特に大規模なデータセットをナビゲートしている場合に便利です。
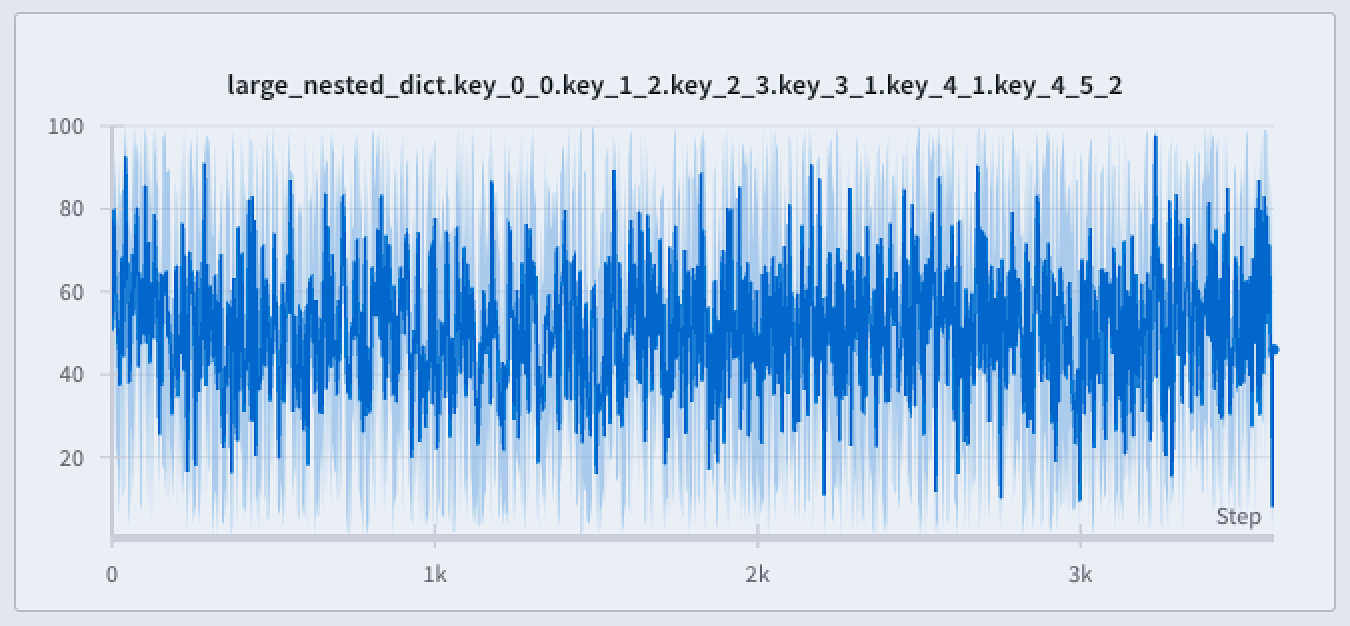
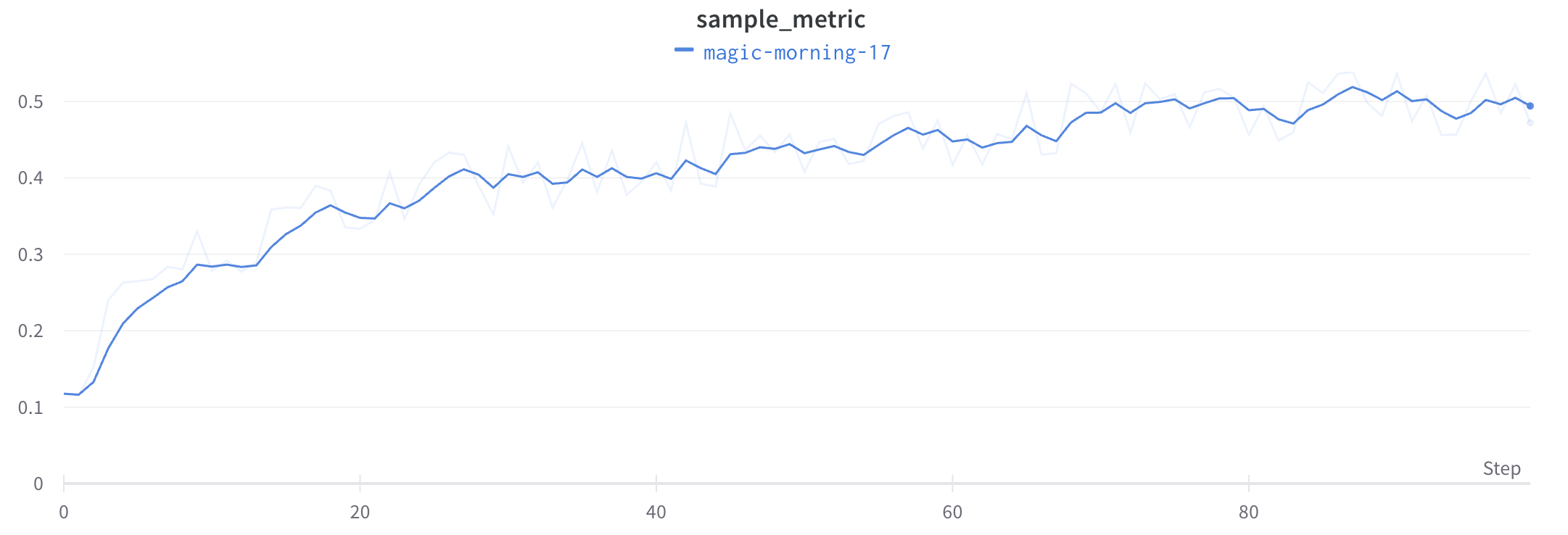
最小値と最大値のレンダリングの設定
線プロットの周囲に影付きのエリアを使って最小値と最大値を表示または非表示にします。
次の画像は、青い線プロットを示しています。薄い青の影付きエリアは各バケットの最小値と最大値を表しています。
線プロットで最小値と最大値をレンダリングする方法は3通りあります:
Never : 最小/最大値は影付きエリアとして表示されません。x軸のバケット全体に渡る集約された線だけを表示します。On hover : グラフにカーソルを合わせると、最小/最大値の影付きエリアが動的に表示されます。このオプションは、ビューをシンプルに保ちながら、範囲をインタラクティブに検査することを可能にします。Always : 最小/最大の影付きエリアは常にグラフのすべてのバケットで一貫して表示され、常に全範囲の値を視覚化するのに役立ちます。これにより、グラフに多くのrunsが視覚化されている場合、視覚的なノイズが発生する可能性があります。
デフォルトでは、最小値と最大値は影付きエリアとして表示されません。影付きエリアオプションの1つを表示するには、以下の手順に従ってください:
All charts in a workspace
Individual chart in a workspace
W&Bプロジェクトに移動します。
左のタブでWorkspace アイコンを選択します。
画面の右上隅にある歯車アイコンを、Add panels ボタンの左側に選択します。
表示されるUIスライダーからLine plots を選択します。
Point aggregation セクション内で、Show min/max values as a shaded area ドロップダウンメニューからOn hover またはAlways を選択します。
W&Bプロジェクトに移動します。
左のタブでWorkspace アイコンを選択します。
フルフィデリティモードを有効にしたい線プロットパネルを選択します。
表示されるモーダル内で、Show min/max values as a shaded area ドロップダウンメニューからOn hover またはAlways を選択します。
データの忠実度を失わずにデータを探索する
データセットの特定の領域を分析し、極値やスパイクなどの重要なポイントを見逃さないようにします。線プロットをズームインすると、W&Bは各バケット内の最小、最大、および平均値を計算するために使用されるバケットサイズを調整します。
W&Bはデフォルトでx軸を1000のバケットに動的に分割します。各バケットに対し、W&Bは以下の値を計算します:
Minimum : そのバケット内の最小値。Maximum : そのバケット内の最大値。Average : そのバケット内のすべてのポイントの平均値。
W&Bは、すべてのプロットでデータの完全な表現を保持し、極値を含める方法でバケット内の値をプロットします。1,000ポイント以下にズームインすると、フルフィデリティモードは追加の集約なしにすべてのデータポイントをレンダリングします。
線プロットをズームインするには、次の手順に従います:
W&Bプロジェクトに移動します。
左のタブでWorkspace アイコンを選択します。
必要に応じて、ワークスペースに線プロットパネルを追加するか、既存の線プロットパネルに移動します。
ズームインしたい特定の領域を選択するためにクリックしてドラッグします。
Line plot grouping and expressions Line Plot Groupingを使用すると、W&Bは選択されたモードに基づいて以下を適用します:
Non-windowed sampling (grouping) : x軸でrunsを超えてポイントを整列させます。複数のポイントが同じx値を共有する場合、平均が取られ、そうでない場合は離散的なポイントとして表示されます。Windowed sampling (grouping and expressions) : x軸を250のバケットまたは最も長い線のポイント数に分割します(いずれか小さい方)。W&Bは各バケット内のポイントの平均を取ります。Full fidelity (grouping and expressions) : 非ウィンドウ化サンプリングに似ていますが、パフォーマンスと詳細のバランスを取るためにrunごとに最大500ポイントを取得します。 Random sampling
Random samplingはラインプロットをレンダリングするために1,500のランダムにサンプリングされたポイントを使用します。大量のデータポイントがある場合、パフォーマンスの理由でランダムサンプリングが有用です。
Random samplingは非決定的にサンプリングします。これは、ランダムサンプリングが時々データ内の重要なアウトライヤーやスパイクを除外し、したがってデータの正確性を低下させることを意味します。
ランダムサンプリングを有効にする
デフォルトでは、W&Bはフルフィデリティモードを使用します。ランダムサンプリングを有効にするには、次の手順に従います:
All charts in a workspace
Individual chart in a workspace
W&Bプロジェクトに移動します。
左のタブでWorkspace アイコンを選択します。
画面の右上隅にある歯車アイコンを、Add panels ボタンの左側に選択します。
表示されるUIスライダーからLine plots を選択します。
Point aggregation セクションからRandom sampling を選択します。
W&Bプロジェクトに移動します。
左のタブでWorkspace アイコンを選択します。
ランダムサンプリングを有効にしたい線プロットパネルを選択します。
表示されるモーダル内で、Point aggregation method セクションからRandom sampling を選択します。
サンプリングされていないデータへのアクセス
W&B Run API を使用して、run中にログされたメトリクスの完全な履歴にアクセスできます。次の例は、特定のrunから損失値を取得し処理する方法を示しています:
# W&B APIを初期化
run = api. run("l2k2/examples-numpy-boston/i0wt6xua" )
# 'Loss'メトリクスの履歴を取得
history = run. scan_history(keys= ["Loss" ])
# 履歴から損失値を抽出
losses = [row["Loss" ] for row in history]
3 - スムーズなラインプロット
ノイズの多いデータにおけるトレンドを見るために、線グラフでスムージングを使用します。
W&B は 3 つのタイプの平滑化をサポートしています:
これらが インタラクティブな W&B レポート でどのように動作するかをご覧ください。
指数移動平均 (デフォルト)
指数平滑化は、時系列データを指数的に減衰させることで、過去のデータポイントの重みを滑らかにする手法です。範囲は 0 から 1 です。背景については 指数平滑化 をご覧ください。時系列の初期値がゼロに偏らないようにするためのデバイアス項が追加されています。
EMA アルゴリズムは、線上の点の密度(x 軸範囲の単位当たりの y 値の数)を考慮に入れます。これにより、異なる特性を持つ複数の線を同時に表示する際に、一貫した平滑化が可能になります。
これが内部でどのように動作するかのサンプルコードです:
const smoothingWeight = Math.min (Math.sqrt (smoothingParam || 0 ), 0.999 );
let lastY = yValues .length > 0 ? 0 : NaN ;
let debiasWeight = 0 ;
return yValues .map ((yPoint , index ) => {
const prevX = index > 0 ? index - 1 : 0 ;
// VIEWPORT_SCALE は結果をチャートの x 軸範囲にスケーリングします
const changeInX =
((xValues [index ] - xValues [prevX ]) / rangeOfX ) * VIEWPORT_SCALE ;
const smoothingWeightAdj = Math.pow (smoothingWeight , changeInX );
lastY = lastY * smoothingWeightAdj + yPoint ;
debiasWeight = debiasWeight * smoothingWeightAdj + 1 ;
return lastY / debiasWeight ;
});
これがアプリ内でどのように見えるかはこちらをご覧ください in the app :
ガウス平滑化
ガウス平滑化(またはガウスカーネル平滑化)は、標準偏差が平滑化パラメータとして指定されるガウス分布に対応する重みを用いてポイントの加重平均を計算します。入力 x 値ごとに平滑化された値が計算されます。
ガウス平滑化は、TensorBoard の振る舞いと一致させる必要がない場合の標準的な選択肢です。指数移動平均とは異なり、ポイントは前後の値に基づいて平滑化されます。
これがアプリ内でどのように見えるかはこちらをご覧ください in the app :
移動平均
移動平均は、与えられた x 値の前後のウィンドウ内のポイントの平均でそのポイントを置き換える平滑化アルゴリズムです。詳細は “Boxcar Filter” を参照してください https://en.wikipedia.org/wiki/Moving_average 。移動平均のために選択されたパラメータは、Weights and Biases に移動平均で考慮するポイントの数を伝えます。
ポイントが x 軸上で不均一に配置されている場合は、ガウス平滑化を検討してください。
次の画像は、アプリ内での移動アプリの表示例を示しています in the app :
指数移動平均 (非推奨)
TensorBoard EMA アルゴリズムは、同じチャート上で一貫したポイント密度を持たない複数の線を正確に平滑化することができないため、非推奨とされました。
指数移動平均は、TensorBoard の平滑化アルゴリズムと一致するように実装されています。範囲は 0 から 1 です。背景については 指数平滑化 をご覧ください。時系列の初期値がゼロに偏らないようにするためのデバイアス項が追加されています。
これが内部でどのように動作するかのサンプルコードです:
data .forEach (d => {
const nextVal = d ;
last = last * smoothingWeight + (1 - smoothingWeight ) * nextVal ;
numAccum ++ ;
debiasWeight = 1.0 - Math.pow (smoothingWeight , numAccum );
smoothedData .push (last / debiasWeight );
これがアプリ内でどのように見えるかはこちらをご覧ください in the app :
実装の詳細
すべての平滑化アルゴリズムはサンプリングされたデータで実行されます。つまり、1500 ポイント以上をログに記録した場合、平滑化アルゴリズムはサーバーからポイントがダウンロードされた後に実行されます。平滑化アルゴリズムの目的は、データ内のパターンを迅速に見つけることです。多くのログを持つメトリクスに対して正確な平滑化された値が必要な場合は、API を介してメトリクスをダウンロードし、自分自身の平滑化メソッドを実行する方が良いかもしれません。
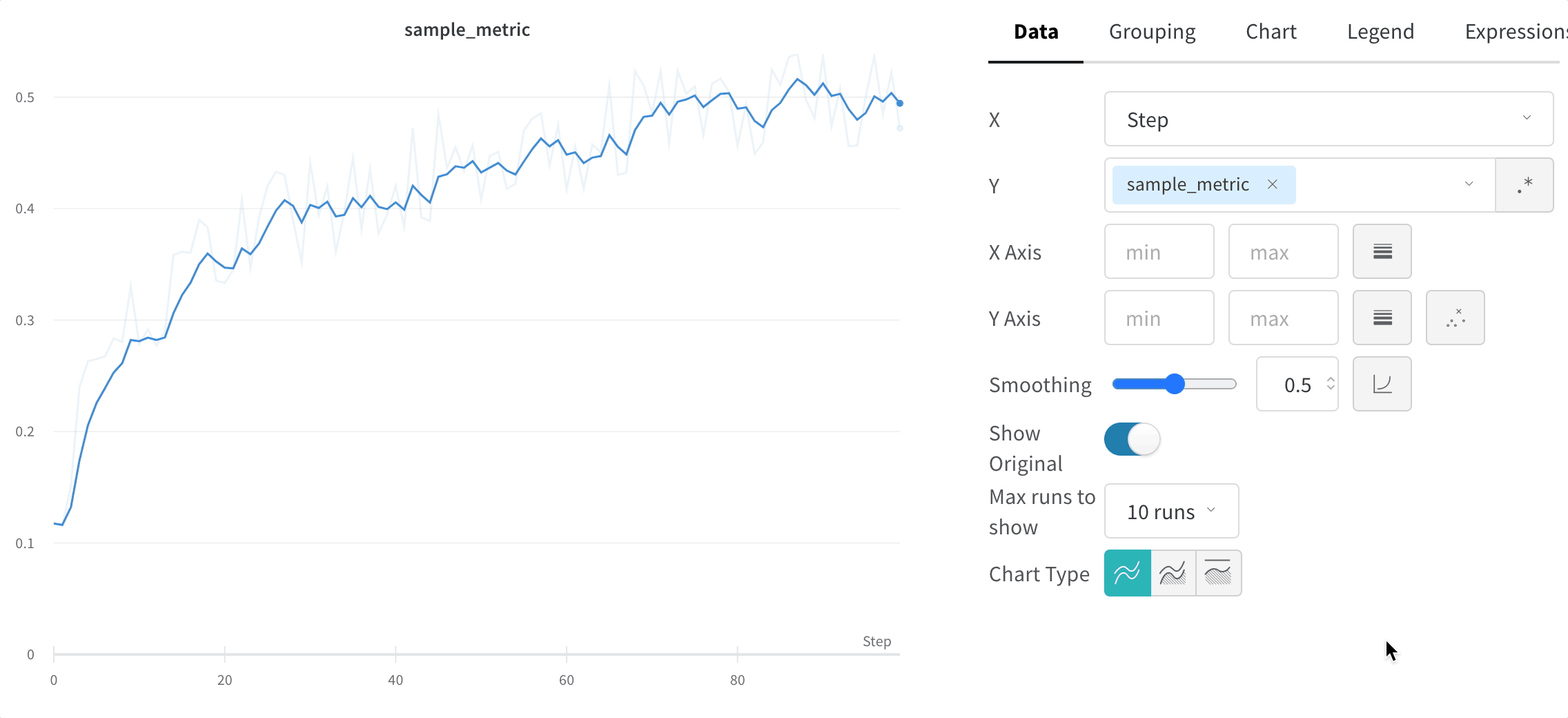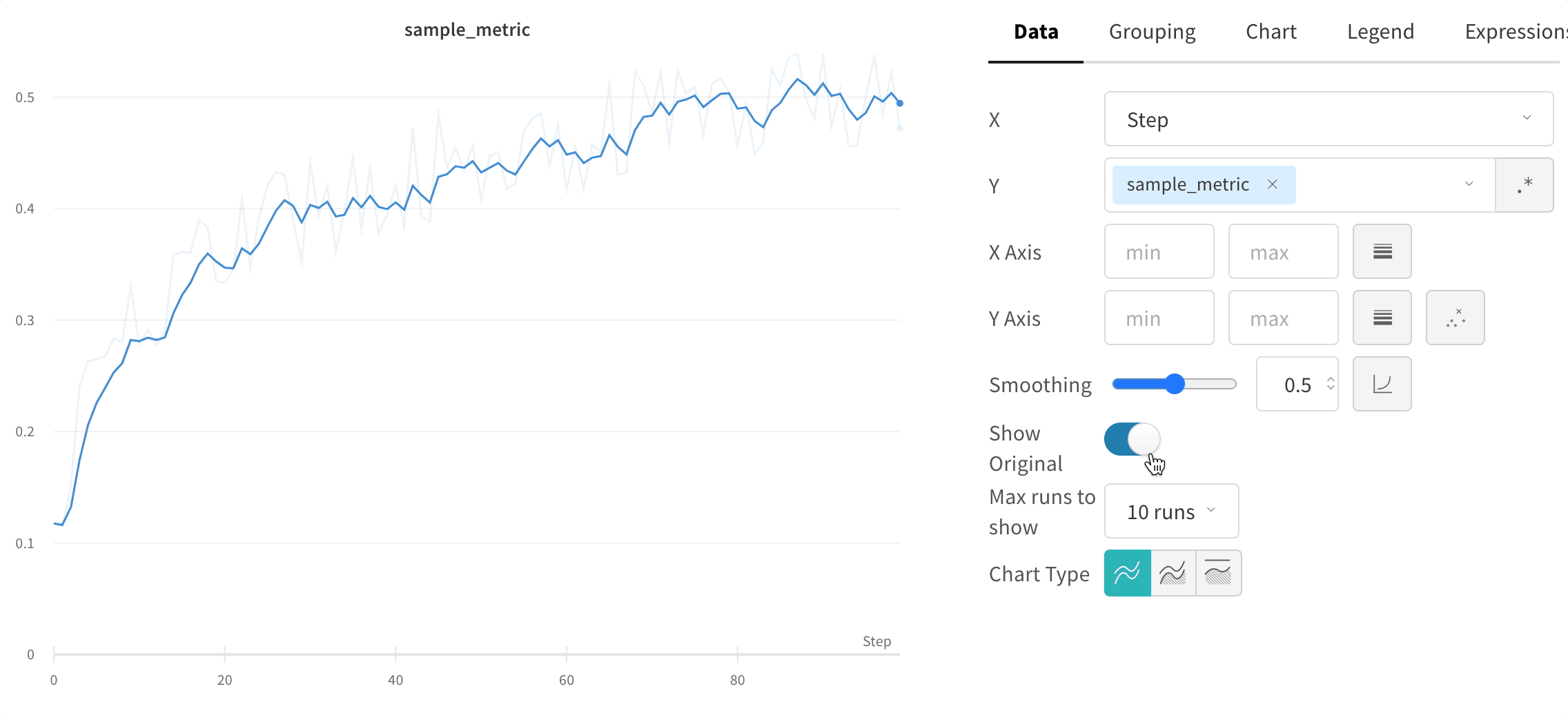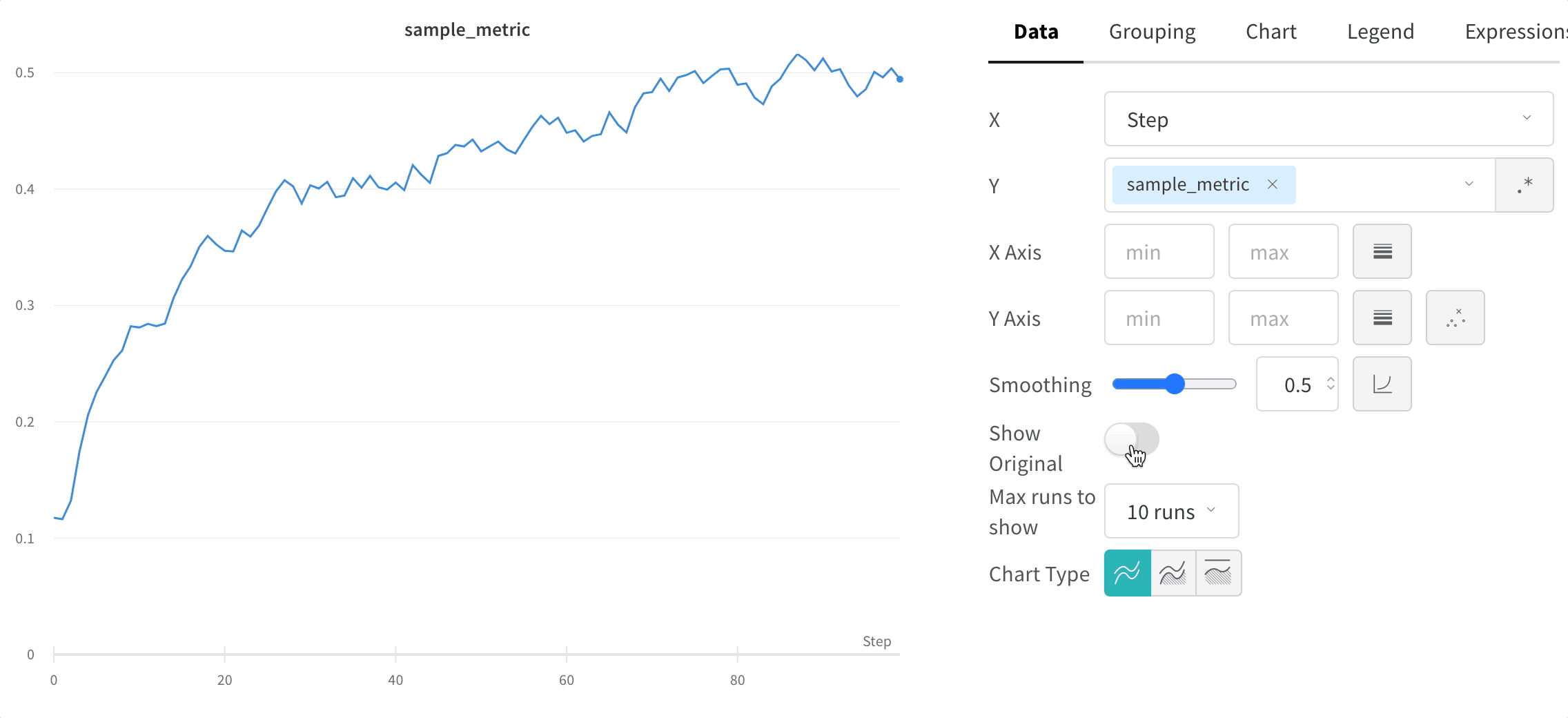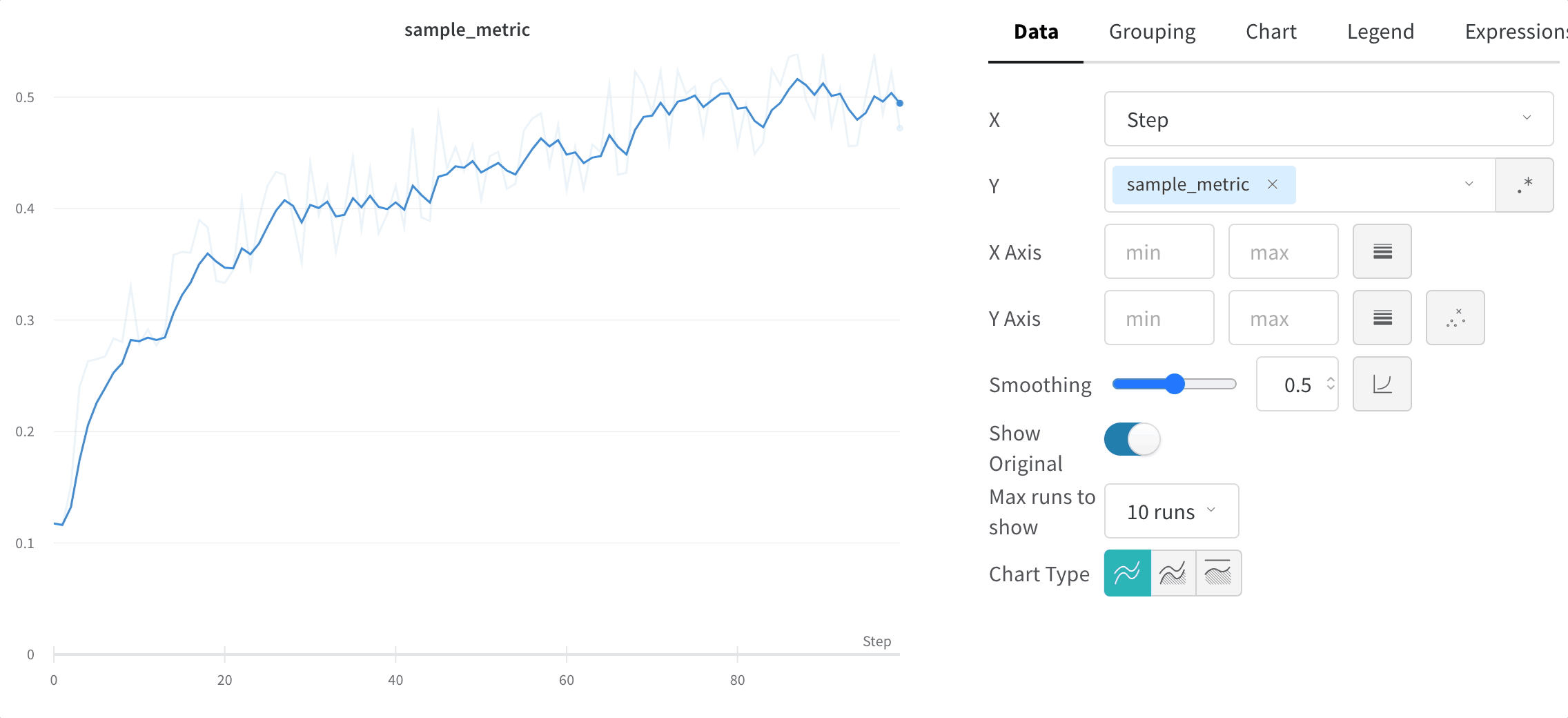
元のデータを非表示にする
デフォルトでは、オリジナルの非平滑化データを背景として薄い線で表示します。この表示をオフにするには、Show Original トグルをクリックしてください。